Índice de contenidos
1. Introducción
En este tutorial vamos a aprender a crear una red neuronal con Spark MLlib, la librería de Machine Learning de Spark, y la vamos a entrenar con datos de vendedores para que aprenda a clasificar aquellos que tienen un pico de ventas.
Vamos a usar dos bases de datos, una de PostgreSQL, que almacena los datos históricos de los clientes y sus propiedades y otra de ElasticSearch, que almacena las ventas que hacen.
Primero explicaremos cómo cargar los datos en spark y cómo procesarlos para poder pasárselos a nuestra red neuronal y luego veremos el funcionamiento interno de esta red neuronal y evaluaremos su eficacia.
A pesar de que este tutorial está hecho íntegramente en Java, Spark también tiene APIs para Scala y Python.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2 Ghz Intel Core i7, 8GB DDR3).
- Sistema Operativo: Mac OS Sierra 10.12.6
- Software:
- Entorno de desarrollo: Eclipse Oxygen 4.7.3
- Postman 6.1.3
- DBeaver 5.1.1
- Docker 18.03.1
- Kitematic 0.17.2
- PostgreSQL 9.5
- elasticDump 3.3.18
3. Configuración inicial
Primero vamos a levantar un docker con PostgreSQL y ElasticSearch. Para ello, en la carpeta de nuestro proyecto creamos un docker-compose:
docker-compose.yml
version: '3'
services:
ml-elasticsearch:
image: elasticsearch:5.0.0
ports:
- "9200:9200/tcp"
- "9300:9300/tcp"
container_name: ml-elasticsearch
ml-kibana:
image: kibana:5.0.0
depends_on:
- ml-elasticsearch
ports:
- "5601:5601/tcp"
container_name: ml-kibana
ml-postgres:
image: postgres:9.5.10
ports:
- "5432:5432/tcp"
environment:
POSTGRES_PASSWORD: example # Use postgres/example user/password credentials
container_name: ml-postgres
Una vez creado abrimos una terminal en la carpeta del proyecto y ejecutamos
docker-compose up
Cuando se hayan cargado los contendores, hacemos Ctrl+C y cerramos la terminal.
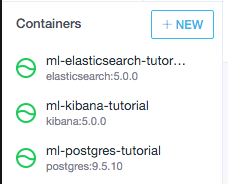
Vamos a Kitematic, y actualizamos la lista de contenedores desde view –> Refresh Container List, y los lanzamos.
Si todo ha ido bien, veremos nuestros contenedores en verde:
![]()
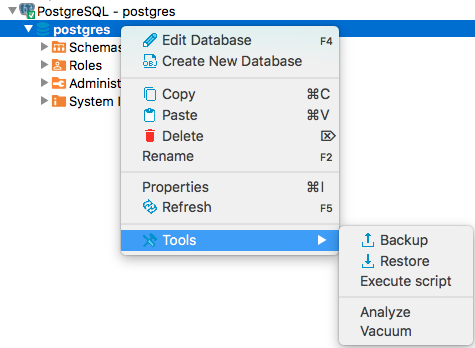
Vamos a cargar ahora la base de datos de PostgreSQL. Para ello nos descargamos las bases de datos, abrimos DBeaver y conectamos con la base de datos que acabamos de levantar. Cargamos la base de datos desde Tools –> Restore:
![]()
Seleccionamos como backup file postgres/postgres.backup y le damos a continuar.
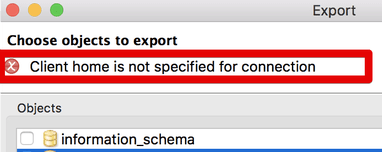
Si nos sale el siguiente error:
![]()
Lo corregimos dando click izquierdo en la conexión -> Properties -> Edit coneection –> Connection settings –> Local Client, y añadimos /Applications/Postgres.app/Contents/Versions/9.5/bin. La seleccionamos y guardamos.
Vamos a cargar ahora la base de datos de ElasticSearch. Para ello descomprimimos el archivo elasticsearch/backup.zip, abrimos una terminal en la carpeta elasticsearch y escribimos:
sh elasticdump_local_all_indices.sh backup http://localhost:9200
Tardará unos 3-5 minutos en importar la base de datos entera.
Podemos comprobar que la base de datos de ElasticSearch se ha cargado correctamente desde Postman.
Importamos el archivo postman/machine learning tutorial.postman_collection.json y podemos lanzar las consultas status y Query todos, que nos dan las siguientes salidas:
status
{
"_shards": {
"total": 1060,
"successful": 530,
"failed": 0
},
"_all": {
...
Query todos
{
"took": 180,
"timed_out": false,
"_shards": {
"total": 530,
"successful": 530,
"failed": 0
},
"hits": {
"total": 462596,
"max_score": 1,
"hits": [
{
...
Hay más consultas preparadas, para poder ejecutarlas es necesario lanzar previamente la consulta Campo idCliente como fielddata.
No vamos a explicarlas en este tutorial, pero nos sirven para comprobar que los datos que cargaremos en Spark se han procesado correctamente.
4. ¡A programar!
El código de este tutorial se puede descargar desde github e importarlo directamente como un proyecto de maven en eclipse o cualquier otro IDE.
En este tutorial explicaremos las partes más importantes del código.
Antes de empezar es necesario añadir las dependencias necesarias a nuestro proyecto, que en nuestro caso son hadoop, las bases de datos y spark y su librería de machine learning.
pom.xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<hadoop.base>2.7.1</hadoop.base>
<spark.version>2.2.1</spark.version>
<scala.version>2.11</scala.version>
<scala.minversion>2.11.0</scala.minversion>
</properties>
<dependencies>
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_{scala.version}</artifactId>
<version>${spark.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_${scala.version}</artifactId>
<version>6.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>2.2.0</version>
</dependency>
<!-- Hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.base}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.base}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.base}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.base}</version>
</dependency>
<!-- DDBB -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.4-1201-jdbc41</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>1.0.1</version>
</dependency>
</dependencies>
4.1. Conectar con las bases de datos
Para poder cargar datos desde postgres creamos la clase SparkPostgresConnection y definimos dos métodos, uno que devuelve la base de datos entera y otra que devuelve sólo el resultado de una query.
SparkPostgresConnection.java
public static Dataset<Row> getData(String ip, String
database, String user, String password, String table){
Map<String, String> options = new HashMap<String, String>();
String url = String.format("jdbc:postgresql://%s:5432/%s?user=%s&password=%s",ip,database,user,password);
options.put("url", url);
options.put("dbtable", table);
options.put("driver", "org.postgresql.Driver");
SparkSession spark = SparkSession.builder().appName("db-example").getOrCreate();
SQLContext sqlContext = new SQLContext(spark);
Dataset<Row> ds = sqlContext.read().format("org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider").options(options).load();
return ds;
}
public static Dataset<Row> getDataFromQuery(Dataset<Row> ds, String tableName, String query){
SparkSession spark = SparkSession.builder().appName("db-example").getOrCreate();
ds.createOrReplaceTempView(tableName);
return spark.sql(query);
}
Vemos que ambos devuelven Dataset<Row>, que es el tipo de datos con los que trabaja Spark. Podemos considerarlos como una tabla, en la que Spark se encarga de distribuir los datos y todas las optimizaciones, y lo hace transparente para nosotros.
getData() conecta con la base de datos y descarga los datos de la table table.
Primero configuramos las opciones de conexión, cargamos la sesión de Spark y el conexto sql.
Una vez que tenemos el contexto sql podemos leer datos de la base de datos, especificando las opciones de conexión. En este caso cargamos todos los datos.
getDataFromQuery() ejecuta una consulta SQL y devuelve los datos obtenidos.
Aprovechamos que ya tenemos los datos descargados previamente para sólo especificar la tabla en la que se hace la consulta y la query.
Para poder cargar datos desde ElasticSearch creamos la clase SparkElasticsearchConnection y definimos los mismos dos métodos de antes.
SparkElasticsearchConnection.java
public static Dataset<Row> getData(String ip, String port) {
SparkConf conf = new SparkConf().setAppName("db-example")
.set("es.nodes", ip)
.set("es.port", port)
.set("es.nodes.wan.only", "true") //Esto es porque está en docker
.set("es.resource", "ventas-*");
SparkSession spark = SparkSession.builder().config(conf).getOrCreate();
SQLContext sql = new SQLContext(spark);
Dataset<Row> solds = JavaEsSparkSQL.esDF(sql);
return solds;
}
public static Dataset<Row> getDataFromQuery(String ip, String port, String query) {
SparkConf conf = new SparkConf().setAppName("db-example")
.set("es.nodes", ip)
.set("es.port", port)
.set("es.nodes.wan.only", "true") //Esto es porque está en docker
.set("es.resource", "ventas-*")
.set("es.query", query);
SparkSession spark = SparkSession.builder().config(conf).getOrCreate();
SQLContext sql = new SQLContext(spark);
return JavaEsSparkSQL.esDF(sql);
}
En getData() sólo es necesario especificar la ip y puerto de elastic.
Especificamos la configuración set(“es.nodes.wan.only”, “true”) porque la base de datos está en docker o en la nube. Si tu caso te lo permite es mejor no especificarla porque afecta mucho al rendimiento.
4.2. Cargar datos en Spark
Primero cargamos el contexto de Spark con:
SparkConf conf = new SparkConf().setAppName("db-example").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
Usamos las funciones que hemos creado para cargar los datos. Cargamos los datos de PostgreSQL con:
Dataset<Row> historico = SparkPostgresConnection.getData("localhost", "postgres", "postgres", "example", "ventas.historico");
Dataset<Row> configuracion = SparkPostgresConnection.getData("localhost", "postgres", "postgres", "example", "ventas.umbrales");
Los datos de elastic los cargamos filtrando primero con una query que nos da los datos de los 90 días anteriores a la fecha especificada.
Si queremos comprobar el resultado de la query a elastic directamente, podemos verla en postman en Query 90 días
String date = "2018-06-12T08:50:01";
String query="{" +
" \"range\" : {" +
" \"timestamp\" : {" +
" \"gte\":\"" + date+ "||-90d\"," +
" \"lt\":\"" + date + "\"" +
" }" +
" }" +
" }";
Dataset<Row> ventas = SparkElasticsearchConnection.getDataFromQuery("localhost","9200", query);
4.3. Procesar los datos
Ahora que tenemos los datos en Spark, vamos a procesarlos para tener en una sola tabla toda la información relevante de las ventas.
De la base de datos de ElasticSearch, que es donde están las ventas, primero obtenemos las ventas que ha hecho cada cliente por hora:
ventas = ventas.withColumn("timestamp_redondeado", col("timestamp").substr(0, 13));
Dataset<Row> ventasAgrupadas = ventas.groupBy(col("detalles.idCliente").as("id_cliente"), col("detalles.pais"), col("timestamp_redondeado")).agg(sum("detalles.cantidad").as("cantidad"));
ventasAgrupadas.cache().show(5);
+----------+----+--------------------+------------------+
|id_cliente|pais|timestamp_redondeado| cantidad|
+----------+----+--------------------+------------------+
| 9999999| SA| 2018-05-08 09| 35486.0|
| 0095465| DE| 2018-03-16 09| 0.0|
| 9999999| AU| 2018-03-16 23|29169.600067138672|
| 1435133| IN| 2018-04-08 08| 25710.0|
| 1433009| IN| 2018-05-31 09| 8280.0|
+----------+----+--------------------+------------------+
only showing top 5 rows
Utilizamos una ventana de 24 horas para añadir a la tabla de ventas una nueva columna que recoge las ventas acumuladas por el cliente en el último día
WindowSpec window24h = Window.partitionBy(col("id_cliente"), col("pais"))
.orderBy(col("timestamp_redondeado").cast("timestamp").cast("long"))
.rangeBetween(-60*60*24, 0);
Dataset<Row> ventasAgrupadasConAnteriores = ventasAgrupadas.select(col("*"), sum("cantidad").over(window24h).alias("cantidad_ultimas_24h"));
ventasAgrupadasConAnteriores.cache().show(5);
+----------+----+--------------------+---------+--------------------+
|id_cliente|pais|timestamp_redondeado| cantidad|cantidad_ultimas_24h|
+----------+----+--------------------+---------+--------------------+
| 1530517| ID| 2018-03-21 05|2040000.0| 2040000.0|
| 1530517| ID| 2018-03-22 04|1.04974E7| 1.25374E7|
| 1530517| ID| 2018-03-29 06| 990000.0| 990000.0|
| 1530517| ID| 2018-06-08 04|1180000.0| 1180000.0|
| 2830006| PH| 2018-03-16 04| 26250.0| 26250.0|
+----------+----+--------------------+---------+--------------------+
only showing top 5 rows
De las bases de datos SQL obtenemos del histórico lo que cada cliente suele vender por día y los umbrales en los que suele trabajar, tanto en porcentaje como en cantidad.
Dataset<Row> ultimoMesDelHistorico = historico.groupBy(col("id_cliente"), col("pais")).agg(max("mes").as("mes"));
Dataset<Row> cantidadHistorico = historico.select(col("id_cliente"),col("pais"),col("cantidad").divide(30).as("ventas_diarias"),col("mes")).join(ultimoMesDelHistorico, joinBy("id_cliente","pais","mes"));
Dataset<Row> historicoYUmbrales = cantidadHistorico.join(configuracion,"pais")
.select(col("id_cliente"),col("pais"),col("ventas_diarias"),col("umbral_cantidad_pico"),col("umbral_cantidad_gran_pico"),col("umbral_porcentaje_pico"),col("umbral_porcentaje_gran_pico"));
historicoYUmbrales.cache().show(5);
+----------+----+--------------------+-------------------+--------------------+-------------------------+----------------------+---------------------------+
|id_cliente|pais|timestamp_redondeado| ventas_diarias|umbral_cantidad_pico|umbral_cantidad_gran_pico|umbral_porcentaje_pico|umbral_porcentaje_gran_pico|
+----------+----+--------------------+-------------------+--------------------+-------------------------+----------------------+---------------------------+
| 6832103| LT| 2018-03-29 14|15025.7666666666667| 50000.00| 100000.00| 500.00| 1000.00|
| 6832103| LT| 2018-03-22 11|15025.7666666666667| 50000.00| 100000.00| 500.00| 1000.00|
| 6832000| LT| 2018-06-08 13|13021.5333333333333| 50000.00| 100000.00| 500.00| 1000.00|
| 6832000| LT| 2018-06-08 12|13021.5333333333333| 50000.00| 100000.00| 500.00| 1000.00|
| 6832000| LT| 2018-06-08 11|13021.5333333333333| 50000.00| 100000.00| 500.00| 1000.00|
+----------+----+--------------------+-------------------+--------------------+-------------------------+----------------------+---------------------------+
only showing top 5 rows
Vemos que para poder hacer join de las tablas hemos usado la función joinBy(), que es una función creada por nostros por comodidad. Esta función simplemente convierte una lista de String en una secuencia de scala:
public static scala.collection.Seq<String> joinBy(String... strings){
List<String> stringList = new ArrayList<String>();
for(String s: strings) stringList.add(s);
return JavaConverters.asScalaIteratorConverter(stringList.iterator()).asScala().toSeq();
}
Combinamos ahora las dos tablas de datos y tendríamos ya todos los datos de entrada para la red neuronal
Dataset<Row> ventasHistoricoYUmbrales = ventasAgrupadasConAnteriores.join(historicoYUmbrales, joinBy("id_cliente","pais"));
Clasificaremos a un cliente como que tiene un pico de ventas si la diferencia entre sus ventas en las últimas 24 horas y lo que suele vender por día se sale de los umbrales que tiene especificados. Para clasificarlo como pico tiene que salirse de los umbrales tanto en cantidad como en porcentaje.
Consideraremos que tiene un gran pico de ventas si esta diferencia se sale de los umbrales que hemos especificado para grandes picos.
Para hacer estas clasificaciones creamos la función:
private static Column calculateAlert(String threshold_amount, String threshold_percentage) {
return ((col(threshold_amount)).lt(col("cantidad_ultimas_24h").minus(col("ventas_diarias"))))
.and((col(threshold_percentage)).lt((col("cantidad_ultimas_24h").minus(col("ventas_diarias"))).divide(col("ventas_diarias")).multiply(100)));
}
Añadiendo las alarmas a nuestra tabla de datos ya tendríamos los datos preparados para que los procese la red neuronal.
Dataset<Row> combinadas = ventasHistoricoYUmbrales.select(
col("cantidad_ultimas_24h"),col("ventas_diarias"),col("umbral_cantidad_pico"),col("umbral_cantidad_gran_pico"),col("umbral_porcentaje_pico"),col("umbral_porcentaje_gran_pico"),
calculateAlert("umbral_cantidad_pico", "umbral_porcentaje_pico").as("pico"),
calculateAlert("umbral_cantidad_gran_pico", "umbral_porcentaje_gran_pico").as("gran_pico"));
Dataset<Row> datos = combinadas.select(col("*"), when(col("gran_pico").equalTo(true), "GRAN_PICO").when(col("pico").equalTo(true), "PICO").otherwise("NO_PICOS").as("picos"));
datos.cache().show(5);
+--------------------+-------------------+--------------------+-------------------------+----------------------+---------------------------+-----+---------+--------+
|cantidad_ultimas_24h| ventas_diarias|umbral_cantidad_pico|umbral_cantidad_gran_pico|umbral_porcentaje_pico|umbral_porcentaje_gran_pico| pico|gran_pico| picos|
+--------------------+-------------------+--------------------+-------------------------+----------------------+---------------------------+-----+---------+--------+
| 116.13999938964844|15025.7666666666667| 50000.00| 100000.00| 500.00| 1000.00|false| false|NO_PICOS|
| 96.58999633789062|15025.7666666666667| 50000.00| 100000.00| 500.00| 1000.00|false| false|NO_PICOS|
| 22469.329894974828|13021.5333333333333| 50000.00| 100000.00| 500.00| 1000.00|false| false|NO_PICOS|
| 22312.679891109467|13021.5333333333333| 50000.00| 100000.00| 500.00| 1000.00|false| false|NO_PICOS|
| 16392.919895410538|13021.5333333333333| 50000.00| 100000.00| 500.00| 1000.00|false| false|NO_PICOS|
+--------------------+-------------------+--------------------+-------------------------+----------------------+---------------------------+-----+---------+--------+
only showing top 5 rows
4.4. Crear la red neuronal
Vamos a crear una clase llamada RedNeuronal que tendrá dos métodos públicos, uno para entrenarla, y otro para clasificar datos una vez finalizado el entrenamiento.
Creamos dos constructores, uno que configura la red neuronal con los valores por defecto y otro que permite especificar estos valores.
Al crear una red neuronal es necesario especificar las neuronas de entrada, que tienen que coicidir con el número de columnas de datos, y las neuronas de salida, que tienen que coincidir con el número de posibles calificaciones de los datos.
public class RedNeuronal {
private static final int DEFAULT_MAX_ITER = 300;
private static final int DEFAULT_BLOCK_SIZE = 128;
private static final long DEFAULT_SEED = System.currentTimeMillis();
private static final int DEFAULT_PORCENTAJE_TEST = 20;
private static final int[] DEFAULT_NEURONAS_INTERMEDIAS = new int[] {10,6,3};
private int neuronasEntrada;
private int neuronasSalida;
private int[] neuronasIntermedias;
private int porcentajeTest;
private long seed;
private int blockSize;
private int maxIter;
private int[] neuronas;
private PipelineModel model;
public RedNeuronal(int neuronasEntrada, int neuronasSalida) {
this(neuronasEntrada, neuronasSalida, DEFAULT_NEURONAS_INTERMEDIAS, DEFAULT_PORCENTAJE_TEST, DEFAULT_SEED, DEFAULT_BLOCK_SIZE, DEFAULT_MAX_ITER);
}
public RedNeuronal(int neuronasEntrada, int neuronasSalida, int[] neuronasIntermedias, int porcentajeTest, long seed, int blockSize, int maxIter) {
this.neuronasEntrada = neuronasEntrada;
this.neuronasSalida = neuronasSalida;
this.neuronasIntermedias = neuronasIntermedias;
this.porcentajeTest = porcentajeTest;
this.seed = seed;
this.blockSize = blockSize;
this.maxIter = maxIter;
this.setNeuronas();
}
private void setNeuronas() {
neuronas = new int[neuronasIntermedias.length+2];
neuronas[0]=neuronasEntrada;
for (int i=0;i<neuronasIntermedias.length;i++) {
neuronas[i+1]=neuronasIntermedias[i];
}
neuronas[neuronasIntermedias.length+1]=neuronasSalida;
}
}
Los parámetros que podemos pasar son:
- neuronasIntermedias: Lista de capas ocultas de la red neuronal.
- porcentajeTest: Porcentaje de datos que no se pasarán al entrenamiento de la red para luego poder comprobar su eficacia. Suele estar entre un 10% y un 40%.
- seed: Semilla para las operaciones pseudoaleatorias. Con la que hay especificada debería valer.
- blockSize: Tamaño de los bloques en que se dividen los datos. El tamaño recomenado es entre 10 y 1000.
- maxIter: Número máximo de iteraciones para parar si el algoritmo no coverge.
Creamos el método public void entrenar(Dataset<Row> datos, String columnaDeClasificacion, String… columnasDeDatos), que entrena la red con una tabla datos pasada.
La red intentará encontrar una manera de deducir el valor de la columna de clasificación a partir de los datos en las columnas de datos.
Primero dividimos la tabla de datos en datos de entrenamiento y de test.
Dataset<Row>[] splits = datos.randomSplit(new double[]{(100-porcentajeTest)/100.0, porcentajeTest/100.0}, seed);
Dataset<Row> train = splits[0];
Dataset<Row> test = splits[1];
El clasificador de la red neuronal necesita que los datos estén en una columna de vectores llamada “features” y que clasificación sea numérica y se llame “label”.
Esto lo conseguimos creando una pipeline en la que aplicamos 4 transformaciones a la tabla de datos:
Primero usamos VectorAssembler() para crear la columna features.
Segundo usamos StringIndexer() para indexar la columna de clasificación en la columna label.
Tercero definimos MultilayerPerceptronClassifier(), que es la red neuronal como tal.
Por último desindexamos los datos clasificados por la red neuronal con IndexToString().
VectorAssembler featureExtractor = new VectorAssembler() //Pasamos todos los datos a procesar a la columna features
.setInputCols(columnasDeDatos)
.setOutputCol("features");
StringIndexerModel labelIndexer = new StringIndexer() //Indexamos las clasificaciones en la columna label
.setInputCol(columnaDeClasificacion)
.setOutputCol("label").fit(datos);
MultilayerPerceptronClassifier trainer = new MultilayerPerceptronClassifier() //Red neuronal. Intenta a partir de las features deducir el label
.setLayers(neuronas)
.setBlockSize(blockSize)
.setSeed(seed)
.setMaxIter(maxIter);
IndexToString labelConverter = new IndexToString() //Pasamos las predicciones a datos legibles
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labels());
Pipeline pipeline = new Pipeline().setStages(new PipelineStage[] {featureExtractor, labelIndexer, trainer, labelConverter});
Por último entrenamos la red neuronal y comprobamos su eficacia
model = pipeline.fit(train);
// Vemos la eficacia del modelo
Dataset<Row> result = model.transform(test);
Dataset<Row> predictionAndLabels = result.select("prediction", "label");
MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator()
.setMetricName("accuracy");
System.out.println("\n\nPorcentaje de error del entrenamiento = " + new DecimalFormat("#.##").format((1.0 - evaluator.evaluate(predictionAndLabels))*100) + "%");
Para acabar con la clase creamos el método que clasifica los datos una vez que ya se ha entrenado la red:
public Dataset<Row> clasificar(Dataset<Row> datos) {
return model.transform(datos);
}
5. Probar y mejorar la red neuronal
Dividimos los datos que hemos procesado en el apartado 4.3 en entrenamiento y test para poder probar la eficiacia de la red que acabamos de crear.
int porcentajeTest=80;
Dataset<Row>[] splits = datos.randomSplit(new double[]{(100-porcentajeTest)/100.0, porcentajeTest/100.0}, System.currentTimeMillis());
Dataset<Row> train = splits[0];
Dataset<Row> test = splits[1];
Entrenamos la red neuronal con los datos que hemos procesado como entradas y con 3 posibles salidas: NO_PICOS, PICO o GRAN_PICO.
Definiendo una sola capa intermedia con 5 neuronas, veamos la eficacia de clasificación de la red.
String [] entradas = new String [] {"cantidad_ultimas_24h", "ventas_diarias", "umbral_cantidad_pico", "umbral_cantidad_gran_pico", "umbral_porcentaje_pico", "umbral_porcentaje_gran_pico"};
RedNeuronal redNeuronal = new RedNeuronal(entradas.length, 3, new int[]{5});
train.cache();
redNeuronal.entrenar(train, "picos", entradas);
//Clasificamos nuestros datos
Dataset<Row> datosClasificados = redNeuronal.clasificar(test);
datosClasificados.cache();
double picos = datosClasificados.filter(col("picos").equalTo("PICO")).count();
double grandesPicos = datosClasificados.filter(col("picos").equalTo("GRAN_PICO")).count();
double noPicos = datosClasificados.filter(col("picos").equalTo("NO_PICOS")).count();
double grandesPicosBienPredecidos = datosClasificados.filter(col("predictedLabel").equalTo("GRAN_PICO")).filter(col("picos").equalTo("GRAN_PICO")).count();
double picosBienPredecidos = datosClasificados.filter(col("predictedLabel").equalTo("PICO")).filter(col("picos").equalTo("PICO")).count();
double noPicosBienPredecidos = datosClasificados.filter(col("predictedLabel").equalTo("NO_PICOS")).filter(col("picos").equalTo("NO_PICOS")).count();
System.out.println(grandesPicosBienPredecidos/grandesPicos*100 + "% de grandes picos bien predecidos");
System.out.println(picosBienPredecidos/picos*100 + "% de picos bien predecidos");
System.out.println(noPicosBienPredecidos/noPicos*100 + "% de no picos bien predecidos\n");
Porcentaje de error del entrenamiento = 3.31%
16.584158415841586% de grandes picos bien predecidos
0.0% de picos bien predecidos
99.97145304025122% de no picos bien predecidos
Vemos que los resultados dejan bastante que desear, pero se pueden mejorar bastante con una configuración diferente de las capas intermedias. Con sólo cambiar:
RedNeuronal redNeuronal = new RedNeuronal(entradas.length, 3, new int[]{20});
Vemos que los resultados mejoran bastante.
Porcentaje de error del entrenamiento = 2.38%
61.73469387755102% de grandes picos bien predecidos
30.844155844155846% de picos bien predecidos
99.54449695382338% de no picos bien predecidos
Podemos mejorar estos resultados aún más, añadiendo un par de columnas de datos de entrada:
Dataset<Row> combinadas = ventasHistoricoYUmbrales.select(
col("cantidad_ultimas_24h"),col("ventas_diarias"),col("umbral_cantidad_pico"),col("umbral_cantidad_gran_pico"),col("umbral_porcentaje_pico"),col("umbral_porcentaje_gran_pico"),
calculateAlert("umbral_cantidad_pico", "umbral_porcentaje_pico").as("pico"),
calculateAlert("umbral_cantidad_gran_pico", "umbral_porcentaje_gran_pico").as("gran_pico"),
(col("cantidad_ultimas_24h").minus(col("ventas_diarias"))).divide(col("ventas_diarias")).multiply(100).as("porcentaje"),
(col("cantidad_ultimas_24h").minus(col("ventas_diarias")).as("resta")));
Dataset<Row> datos = combinadas.select(col("*"), when(col("gran_pico").equalTo(true), "GRAN_PICO").when(col("pico").equalTo(true), "PICO").otherwise("NO_PICOS").as("picos")).filter(col("porcentaje").isNotNull());
String [] entradas = new String [] {"cantidad_ultimas_24h", "ventas_diarias", "umbral_cantidad_pico", "umbral_cantidad_gran_pico", "umbral_porcentaje_pico", "umbral_porcentaje_gran_pico", "resta", "porcentaje"};
Vemos que llegamos a tasas de acierto cercanas al 100%
Porcentaje de error del entrenamiento = 1.34%
93.0990099009901% de grandes picos bien predecidos
76.62145110410094% de picos bien predecidos
99.10092807424594% de no picos bien predecidos
6. Conclusiones
Hemos visto lo relativamente rápido y sencillo que es crear con Spark una herramienta tan potente como es una red neuronal.
En este tutorial hemos usado una red neuronal, pero Spark nos da la posibilidad de usar otro tipo de clasificadores como árboles de decisión, Naive Bayes, etc, y la base sería la misma que hemos seguido.
7. Apéndice: árboles de decisión
Podemos cambiar nuestro clasificador y en vez de tener una red neuronal, ponemos un árbol de decisión. Para ello nos basta con cambiar la línea:
MultilayerPerceptronClassifier trainer = new MultilayerPerceptronClassifier() //Red neuronal. Intenta a partir de las features deducir el label
.setLayers(neuronas)
.setBlockSize(blockSize)
.setSeed(seed)
.setMaxIter(maxIter);
por:
DecisionTreeClassifier trainer = new DecisionTreeClassifier()
.setMaxBins(512)
.setMaxDepth(30);
Vemos la potencia de los árboles de decisión, ya que incluso sin añadir las columnas “resta” y “porcentaje”, tenemos tasas de aciertos mejores que con la red neuronal:
Porcentaje de error del entrenamiento = 0.44%
99.70945392237205% de aciertos
98.60627177700349% de grandes picos bien predecidos
89.0909090909091% de picos bien predecidos
99.91483431402911% de no picos bien predecidos









































![An American Tail [1986] [DVD5-R1] [Latino]](http://iili.io/FjktrS2.jpg)

