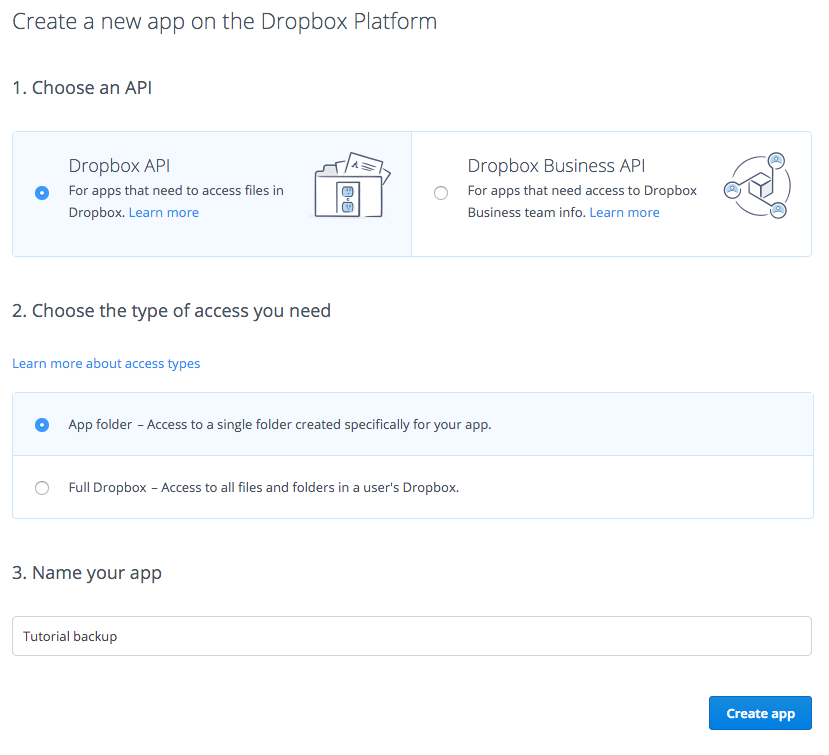
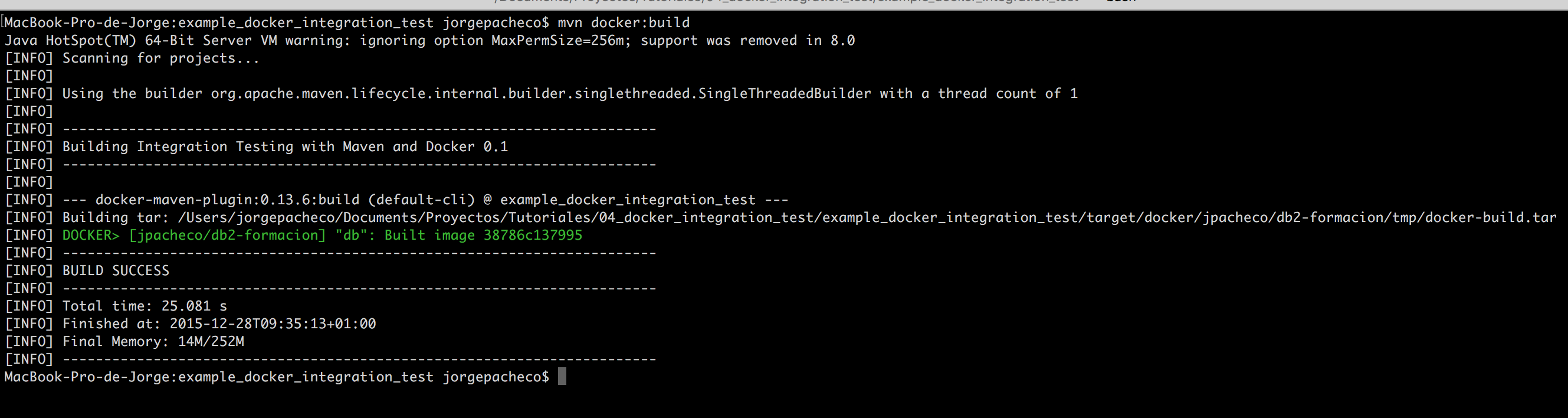
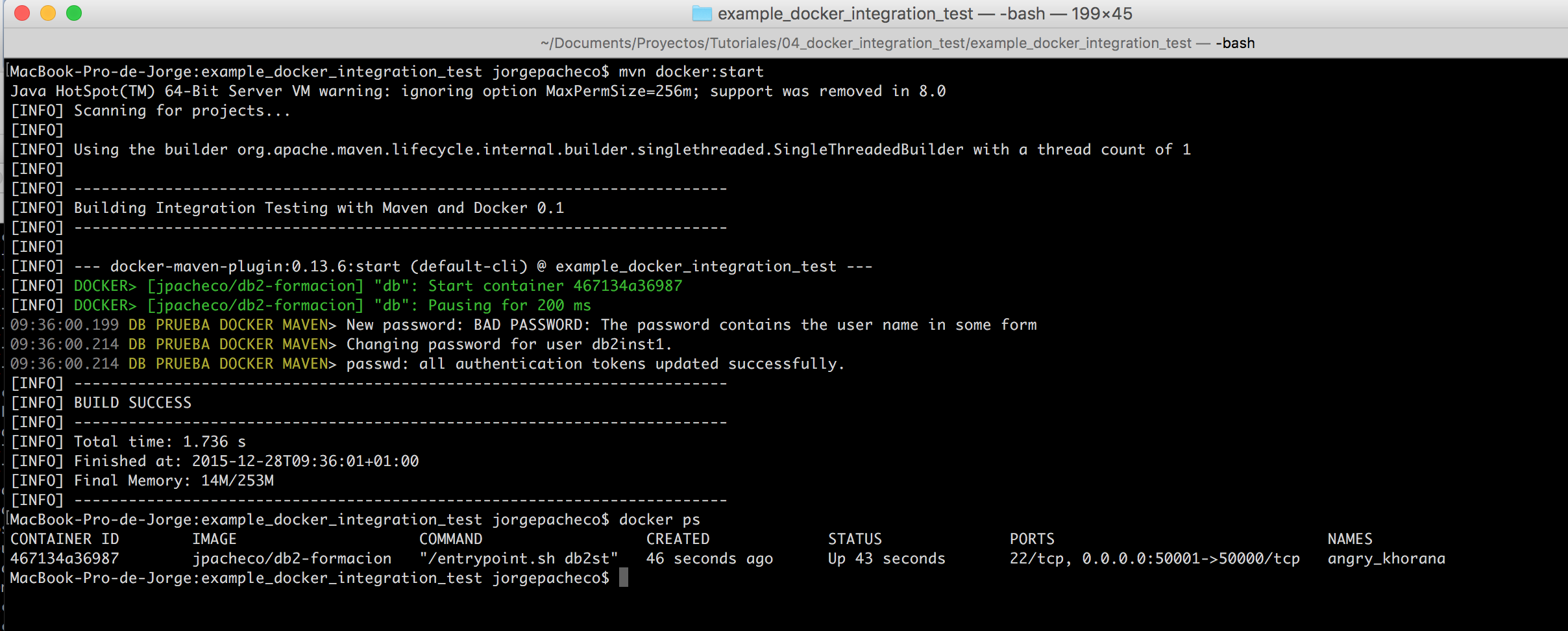
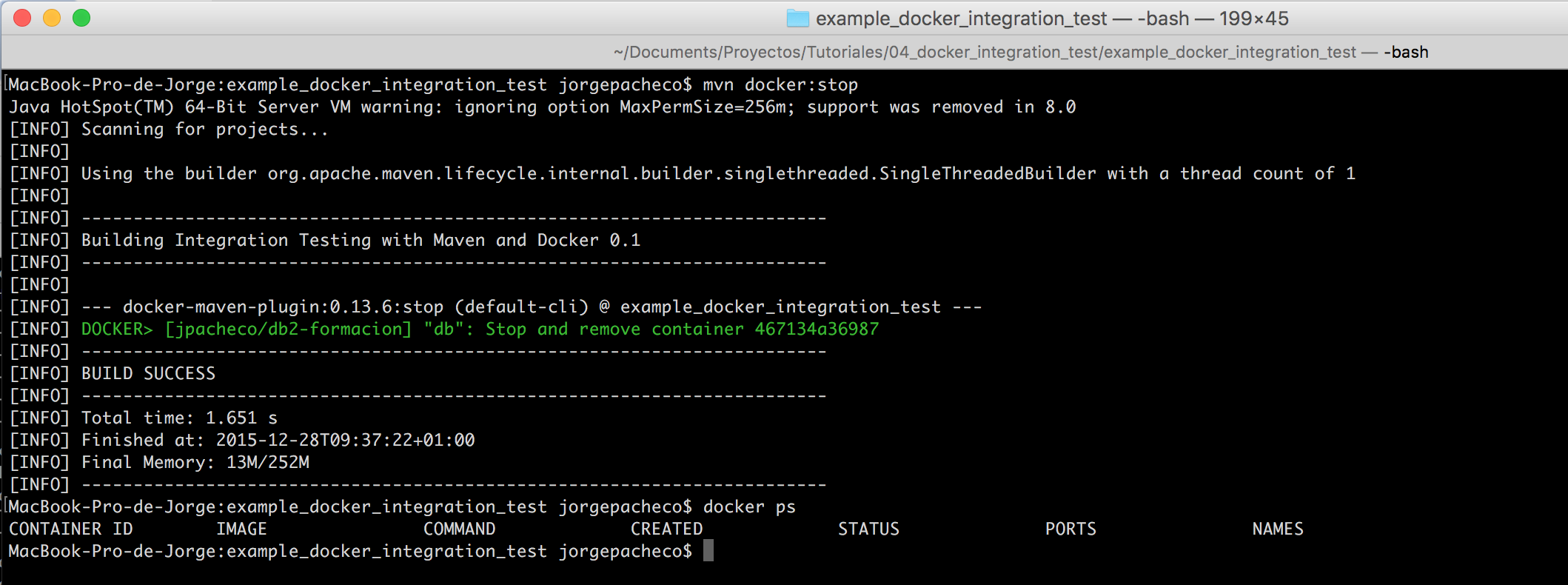
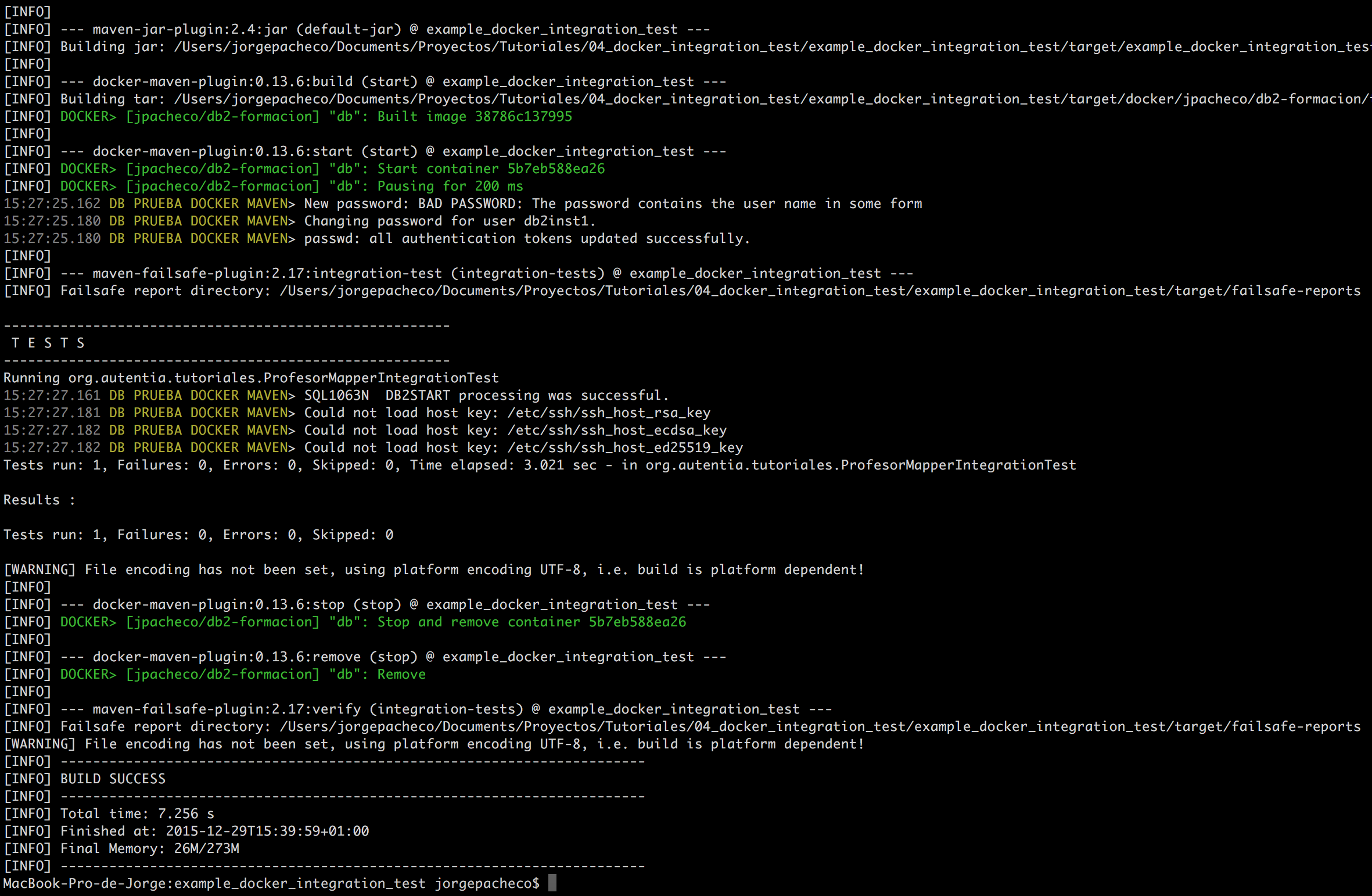
En este tutorial vamos a ver un ejemplo de desarrollo con TDD en NodeJS, empleando Mocha y Chai. Lo usaremos para normalizar (ajustar volumen) el audio de unos vídeos con la librería FFMpeg
0. Índice de Contenidos
1. Entorno
Este tutorial está escrito usando el siguiente entorno:
- Acer Aspire One 753 (2 Ghz Intel Celeron, 4GB DDR2)
- Ubuntu 15.10
- NPM 1.4.21
- NodeJS v0.10.25
- FFMpeg 2.7.3
Puedes descargar el código de este tutorial en https://github.com/4lberto/VideoAudioNormalizer
2. Problema a Resolver
En Autentia estamos grabando cursos on-line de nuestras especialidades. Para ello, usamos normalmente la modalidad de screencast que grabamos en una cámara especial de grabación para que el audio tenga cierta calidad: sin reverberaciones ni interferencias externas. Además empleamos un buen micrófono de grabación.
El audio de los vídeos es fantástico (salvo por el narrador jeje), pero quizá el nivel no sea el adecuado: posiblemente es demasiado bajo, lo que puede causar molestias a los alumnos, que deberán ajustar el audio de su sistema en exclusiva para estos vídeos.
El nivel de audio se mide en decibelios (dB). Al ser un fichero del que se lee, el nivel final dependerá de cómo lo reproduzca el usuario. Por eso, se establecen valores negativos, que luego serán amplificados.
El objetivo será aumentar el volumen de cada vídeo hasta cierto nivel establecido. Para complicarlo un poco más y ampliar nuestro campo de trabajo, vamos a hacerlo en NodeJS.
Para ello se seguirá la siguiente lógica:
- Obtener el volumen máximo del vídeo, por ejemplo -5.7dB.
- Aumentar el volumen máximo hasta llegar a 0.0dB. Por tanto, subir ese vídeo en 5.7dB positivos.
Si algún ingeniero de sonido lee esto seguro que me mata, pero para las grabaciones que hemos hecho y lo que buscamos no es suficiente. También podría tomar el volumen medio y subirlo hasta un nivel determinado, pongamos -20.0dB, pero no quería tampoco hacer “clipping“.
No obstante, el programa está disponible en GitHub, así que puedes hacer un fork y tunearlo a tu gusto.
3. FFMpeg
Para tratar el vídeo nos hace falta una biblioteca de tratamiento de vídeo y audio, como es FFMpeg. Puede ser descargada en: https://www.ffmpeg.org/.
Esta herramienta nos va a permitir analizar los vídeos y transformarlos con las instrucciones que indiquemos para alterar el volumen del audio y que lo amplifique. Vamos a ver cómo usarlo.
3.1. Instalando FFMpeg
FFMpeg es muy fácil de instalar. O bien lo podemos descargar de su página oficial, eligiendo el sistema operativo de nuestro ordenador: Mac, Windows o varias distribuciones de Linux, o podemos emplear el gestor de paquetes de nuestro sistema operativo.
Si te lo vas a descargar es muy fácil: se baja un fichero comprimir en cuyo interior está el ejecutable que se utiliza, ¡nada más! Una vez se tiene el ejecutable lo podemos referenciar en el path del sistema para que al escribir “ffmpeg” en cualquier lado, el sistema responda.
Como estoy usando Ubuntu 15.10 voy a usar el gestor synaptic. No puede ser más fácil.
sudo apt-get install ffmpeg -y
Esperamos un poco y ya lo tenemos instalado. Sin ningún problema :).
El gestor de paquetes lo mete en el path, así que probamos directamente a escribir en un terminal “ffmpeg” y vemos que funciona sin problemas:
ffmpeg
El resultado debería ser algo de este estilo:
ffmpeg version 2.7.3-0ubuntu0.15.10.1 Copyright (c) 2000-2015 the FFmpeg developers
built with gcc 5.2.1 (Ubuntu 5.2.1-22ubuntu2) 20151010
configuration: --prefix=/usr --extra-version=0ubuntu0.15.10.1 --build-suffix=-ffmpeg --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --enable-gpl --enable-shared --disable-stripping --enable-avresample --enable-avisynth --enable-frei0r --enable-gnutls --enable-ladspa --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libmodplug --enable-libmp3lame --enable-libopenjpeg --enable-openal --enable-libopus --enable-libpulse --enable-librtmp --enable-libschroedinger --enable-libshine --enable-libspeex --enable-libtheora --enable-libtwolame --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libxvid --enable-libzvbi --enable-opengl --enable-x11grab --enable-libdc1394 --enable-libiec61883 --enable-libzmq --enable-libssh --enable-libsoxr --enable-libx264 --enable-libopencv --enable-libx265
libavutil 54. 27.100 / 54. 27.100
libavcodec 56. 41.100 / 56. 41.100
libavformat 56. 36.100 / 56. 36.100
libavdevice 56. 4.100 / 56. 4.100
libavfilter 5. 16.101 / 5. 16.101
libavresample 2. 1. 0 / 2. 1. 0
libswscale 3. 1.101 / 3. 1.101
libswresample 1. 2.100 / 1. 2.100
libpostproc 53. 3.100 / 53. 3.100
Hyper fast Audio and Video encoder
usage: ffmpeg [options] [[infile options] -i infile]... {[outfile options] outfile}...
3.2. Aplicando FFMpeg a los vídeos
FFMpeg tiene multitud de opciones entre las que tuve que navegar para encontrar lo que quería. Básicamente quería dos cosas:
- Obtener el valor del nivel de audio máximo para el vídeo.
- Alterar el valor del vídeo.
Para conocer el valor del nivel máximo de audio de un vídeo, ejecutaremos en nuestra línea de comandos la siguiente instrucción:
ffmpeg -i INPUT.mp4 -af "volumedetect" -f null /dev/null
Donde INPUT.mp4 es el vídeo del cual queremos conocer el volumen máximo. La salida es bastante extensa, y puede llevar un rato en procesarse, dependiendo del tamaño y calidad del vídeo. Lo que nos interesa es la parte final:
video:12kB audio:2988kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
[Parsed_volumedetect_0 @ 0x1948820] n_samples: 1529856
[Parsed_volumedetect_0 @ 0x1948820] mean_volume: -41.0 dB
[Parsed_volumedetect_0 @ 0x1948820] max_volume: -10.7 dB
[Parsed_volumedetect_0 @ 0x1948820] histogram_10db: 34
[Parsed_volumedetect_0 @ 0x1948820] histogram_11db: 81
[Parsed_volumedetect_0 @ 0x1948820] histogram_12db: 72
[Parsed_volumedetect_0 @ 0x1948820] histogram_13db: 41
[Parsed_volumedetect_0 @ 0x1948820] histogram_14db: 35
[Parsed_volumedetect_0 @ 0x1948820] histogram_15db: 34
[Parsed_volumedetect_0 @ 0x1948820] histogram_16db: 55
[Parsed_volumedetect_0 @ 0x1948820] histogram_17db: 72
[Parsed_volumedetect_0 @ 0x1948820] histogram_18db: 112
[Parsed_volumedetect_0 @ 0x1948820] histogram_19db: 267
[Parsed_volumedetect_0 @ 0x1948820] histogram_20db: 347
[Parsed_volumedetect_0 @ 0x1948820] histogram_21db: 485
Y específicamente nos interesan estas líneas.
[Parsed_volumedetect_0 @ 0x1948820] n_samples: 1529856
[Parsed_volumedetect_0 @ 0x1948820] mean_volume: -41.0 dB
[Parsed_volumedetect_0 @ 0x1948820] max_volume: -10.7 dB
Podemos ver el volumen medio (mean_volume) y el máximo (max_volume). En el vídeo que hemos utilizado es de -10.7dB, así que subiremos el volumen general 10.7dB para que el volumen máximo final sea de 0.0dB. O si lo prefieres puedes acercarte algo menos a 0.0dB, como por ejemplo dejándolo en -5.0dB.
También si quieres puede usar el volumen medio… aunque correrías el riesgo de cortar alguna señal por volumen máximo…
Para la segunda parte, que sería ordenar subir 10.7dB positivos al volumen del audio del vídeo, tenemos este comando:
ffmpeg -i INPUT.mp4 -af "volume=10.7dB" -strict -2 INPUT_NORMALIZED.mp4
Donde INPUT.mp4 es el fichero al que le vamos a aplicar la transformación, e INPUT_NORMALIZED.mp4 es el fichero de salida.
Esto es todo lo que debemos conocer de FFMpeg para hacer nuestro programa para normalizar audio de nuestros vídeos.
Como podrás suponer, la dificultar radica en ejecutar FFMpeg, recoger el resultado de salida y aplicar el segundo comando correctamente. Vamos a ver cómo hacemos todo esto en NodeJs.
4. Proyecto en NodeJS
Vamos con lo más interesante, porque lo anterior es sólo un pretexto para tener algo que hacer con nodeJS :).
Deberías tener instalado NodeJS y NPM en tu sistema. Ya hay otros tutoriales en los que explicamos cómo hacerlo. Por ejemplo este en el que hablo de Polymer y que necesitamos nodeJS y NPM para montar el entorno: Introducción a Polymer. Por tanto no voy a repetir aquí la instalación. Asumimos que los tienes instalados, listos para usar, al menos en las versiones que indico en el apartado Entorno.
4.1. Creación de la estructura
Comencemos creando el proyecto en un directorio determinado que hemos reservado en nuestro ordenador.
mkdir ffmpeg
cd ffmpeg
Ahora iniciamos el package.json con npm. Aquí residirá la metainformación del proyecto de NodeJS y las dependencias, así que tómatelo en serio ![:)]()
npm init
Completa la información que pide: nombres, versiones, GitHub…
Ahora debemos instalar las dependencias, que serán:
- Chai 3.4.1
- Mocha 2.3.4
- fluent-ffmpeg 2.0.1
Las dos primeras son en tiempo de desarrollo y la tercera forma parte del programa. Para instalarlas haremos:
npm install -D mocha
npm install -D chai
npm install --save fluent-ffmpeg
El fichero package.json debería quedar algo así:
{
"name": "ffmpeg",
"version": "0.0.1",
"description": "NormalizeAudios",
"main": "audio.js",
"dependencies": {
"fluent-ffmpeg": "^2.0.1"
},
"devDependencies": {
"chai": "^3.4.1",
"mocha": "^2.3.4"
},
"scripts": {
"test": "mocha"
},
"repository": {
"type": "git",
"url": "https://github.com/4lberto/VideoAudioNormalizer.git"
},
"keywords": [
"audio",
"video",
"normalize",
"ffmpeg"
],
"author": "4lberto",
"license": "ISC",
"bugs": {
"url": "https://github.com/4lberto/VideoAudioNormalizer/issues"
}
}
El siguiente paso consiste en crear un directorio “libs” donde residirán los módulos auxiliares de la aplicación, y otro “test” donde estarán los ficheros de test que se ejecutarán con Mocha. Muy fácil:
mkdir test
mkdir libs
Finalmente vamos a instalar Mocha para que pueda ejecutar los test desde línea de comandos. Efectivamente, si escribimos “mocha” en nuestra shell, debería funcionar, sino lo hace, lo tenemos que instalar con NPM, haciendo uso de la opción “-g” para indicar que es una instalación global a todo el sistema.
npm install -g mocha
Ahora si escribimos mocha, y tenemos el directorio test creado pero vacío, debería responder con esta salida:
0 passing (1ms)
4.2. Comienzo del desarrollo
Antes de comenzar con el desarrollo del programa, vamos a ver en primer lugar una característica muy importante de NodeJS que va a influir determinantemente en cómo se desarrolla: los módulos.
4.2.1. El sistema de Módulos de NodeJS
NodeJS está basado en módulos. Los módulos, sin entrar mucho en detalle, son conjuntos de funciones agrupadas en un único archivo. De este modo, dentro de nuestro fichero de NodeJS podemos cargar otros módulos sobre los que nos podemos apoyar. Y por supuesto, también podemos crear nuestros propios módulos.
Podrás imaginar entonces la importancia de NPM y la gestión de dependencias en NodeJS: puedes instalar cualquier módulo y hacer uso de él muy fácilmente. ¿Cómo lo hago? Es muy fácil: utilizando la función require(“nombreMódulo”). Así es cómo cargamos el módulo nativo FS (FileSystem) de NodeJS:
var fs = require("fs");
fs.exists("/etc/hosts", function(res){console.log(res);})
Con estas sencillas instrucciones (vete acostumbrado al mundo de los callback), hemos logrado consultar si el archivo “/etc/hosts” existe en nuestro sistema.
Como puedes ver, se asigna el módulo a la variable “fs” y luego se hace uso de ella. El parámetro de require(“fs”) indica el módulo que se quiere cargar. Así, se puede indicar por el nombre directamente o por el fichero. Algunos módulos forman parte del core de NodeJS, otros están instalados globalmente, otros son del propio proyecto, y finalmente otros son simplemente ficheros que cargar. Por tanto, la notación soporta parámetros del estilo:
var modulo = require("./directorio/fichero.js");
La función require realiza una búsqueda según unos ciertos criterios.
¿Cómo puedo crear mis propios módulos? Aquí es donde vamos… Simplemente creando un fichero de JavaScript que contiene las funciones. Pero hay una cosa más… tienes que exportar esas funciones para que sean accesibles desde el exterior. No todas las funciones y contenidos son expuestos cuando son importados.
En todo módulo hay un objeto implícito llamado “module”, que referencia al objeto que representa el módulo actual. No es una referencia global al programa, sino que es algo del propio módulo que estamos creando. Dentro de las propiedades del objeto “module” hay varias, como referencia a las dependencias, si está cargado o no, carga de otros módulos, pero sobre todo nos interesa “exports”. Con module.exports indicamos qué funciones pueden ser empleadas por los módulos que hacen la carga de éste. Como es muy usado, tiene un alias que es simplemente “exports”. Lo vemos mejor en código.
Vamos a crear un módulo de operaciones aritméticas. La típica calculadora con suma y resta:
module.exports.suma = function(a,b){return a+b};
module.exports.resta = function(a,b){return a-b};
Y ya está… como module.exports tiene una variable exports (es decir exports = module.exports), lo podríamos haber reducido a:
exports.suma = function(a,b){return a+b};
exports.resta = function(a,b){return a-b};
Imagina que guardamos este código en el fichero “calculadora.js”. ¿Cómo lo usamos en otro módulo?
var calculadora = require("./calculadora.js");
console.log("La suma de 2 y 3 es:" + calculadora.suma(2,3));
Básicamente esto es lo que debemos saber acerca de los módulos. Hay otros detalles, pero son más avanzados. Sabiendo esto, tenemos suficiente para adentrarnos en la aplicación.
4.2.2. Organización del código
Con este mecanismo de módulos, se me ha ocurrido crear la siguiente estructura:
- Fichero principal ejecutable: audioNormalized.js
- Directorio para archivos auxiliares:libs
- Fichero para funciones principales: audioLib.js
- Fichero para funciones auxiliares: utils.js
- Directorio para test(TDD):tests
- Fichero de test para funciones principales: audioLibTest.js
- Fichero de test para funciones auxiliares: utilsTest.js
Quizá no sea la mejor opción de organizar todo, pero sí que me ha permitido aplicar un poco de TDD para la construcción. La aplicación es relativamente sencilla, así que no hay problemas. En código:
touch audioNormalizad.js
mkdir libs
touch ./libs/audioLib.js
touch ./libs/utils.js
mkdir test
touch ./test/audioTest.js
touch ./test/utilsTest.js
4.3. Aplicando TDD
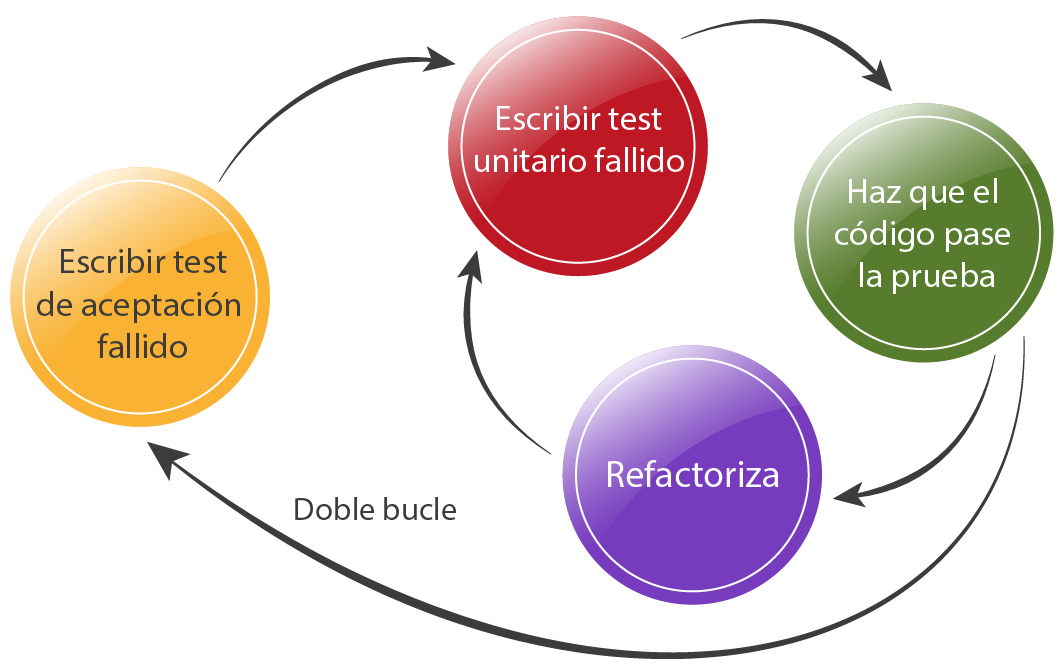
Es hora de empezar a programar, y para ello vamos a hacer TDD: se trata de hacer primero los test y luego hacer el código que cumple los test. En realidad es algo más elaborado. Puedes echar un ojo a una crítica que hice del libro en el que se basa, y donde explico en qué consiste en esta entrada.
4.3.1. Mocha y Chai
Pero para hacer TDD necesitamos un sistema para hacer test. La parte buena de NodeJS es que hereda los sistemas de test existentes para JavaScript, que además, últimamente está teniendo un empuje enorme.
Para este tutorial me he decantado por Mocha y Chai. Mocha es un framework de testing que da soporte para ejecutar test en Javascript. Chai por su parte es una librería de “asserts”, es decir, facilita expresar los predicados que tienen que cumplir los test. Algo así como que hace sencillo escribir en código “el resultado debe estar entre 5 y 50”.
En secciones anteriores ya hemos explicado cómo instalar Mocha y Chai (via npm). Incluso si hemos instalado globalmente Mocha (npm install -g mocha) disponemos del comando “mocha” en nuestro ordenador.
4.3.2. Comenzando TDD
Comenzamos ejecutando el comando mocha en nuestro terminal en el directorio raíz. Como hemos creado el subdirectorio “test” con dos ficheros vacíos, Mocha encontrará 0 test que ejecutar:
0 passing (1ms)
Esto es una buena noticia porque ya tenemos un punto de partida. Vamos a hacer TDD: primero hacemos un tests de una necesidad. Se me ocurre que en primer lugar necesitamos obtener una lista de ficheros de una extensión determinada (vídeos) de un directorio sobre el que actuar. Vamos a expresarlo en un test.
var utils = require('../libs/utils');
var chai = require('chai');
var DIR = './test/';
var VIDEO_EXTENSION = 'mp4';
describe('getFilesFromDirWithExtension', function() {
it("Should get more than 0 files from the dir", function(){
chai.assert.isAbove(utils.getFilesFromDirWithExtension(DIR, VIDEO_EXTENSION).length,0);
});
Bueno, en realidad se trata de un test de integración porque tenemos que preparar el entorno. Hay algunas cosas interesantes que nos van a forzar a programar, más allá del test:
- Que el fichero donde va a estar la función que vamos a testear es utils.js.
- Que debemos cargar algún fichero de extensión mp4 en el directorio “test”.
- Que la función se va a llamar “getFilesFromDirWithExtension” y que tiene dos parámetros: el directorio y la extensión.
Ya tenemos el test. Pues lo ejecutamos para ver nuestra primera bandera roja:
getFilesFromDirWithExtension
1) Should get more than 0 files from the dir
0 passing (4ms)
1 failing
1) getFilesFromDirWithExtension Should get more than 0 files from the dir:
TypeError: Object # has no method 'getFilesFromDirWithExtension'
at Context. (test/utilsTest.js:9:29)
He ido demasiado rápido estableciendo el test completo, debería haber ido más despacio, pero nos podríamos eternizar… Vamos a ver qué código hace que se cumpla el test:
var fs = require("fs");
var getFilesFromDirWithExtension = function(directory, extension){
return fs.readdirSync(directory).filter(function(element){
return element.substr(element.length-3,element.length)==extension;
});
};
exports.getFilesFromDirWithExtension = getFilesFromDirWithExtension;
Si te fijas, he creado la variable para asignarla a la función y en un segundo paso, en la última línea se ha hecho la asignación a exports, que recuerda, es el equivalente de module.exports, y se usa para que los otros módulos que hagan un require, puedan utilizar la función.
Otra cosa que te llamará la atención es que se hace uso del módulo “fs” de NodeJS, que se emplea para el manejo de archivos. Así podemos obtener con readdirSync todos los archivos de un directorio indicado. Posteriormente lo filtramos con filter para quedarnos con los de extensión deseada.
Ahora ponemos un fichero con extensión .mp4 en el directorio test y ejecutamos Mocha. Esta vez tenemos buenas noticias:
getFilesFromDirWithExtension
✓ Should get more than 0 files from the dir
1 passing (3ms)
¡Ya tenemos nuestro primer test pasado! Ahora es cuestión de ir añadiendo más y mas test hasta completar la funcionalidad.
No voy a poner el código de todos los test de la parte de utilidades que realicé. Voy a enumerar algunos de ellos simplemente:
- Que devuelva solamente los ficheros de la extensión indicada.
- Que tome el valor de la salida de FFmpeg correspondiente al volumen máximo con 1 entero y 1 decimal.
- Que tome el valor de la salida de FFmpeg correspondiente al volumen máximo con 2 entero y 1 decimal.
- Que tome el valor de la salida de FFmpeg correspondiente al volumen máximo con 4 entero y 1 decimal.
- Que dado un valor en dB negativos le invierta el signo.
- Que dado un valor en dB positivos le invierta el signo.
- Que dado un nombre de fichero le añada “_NORMALIZED” al final del nombre.
Una vez que ya tenemos las funciones de util.js, que son las básicas, podemos ponernos con las principales del fichero audioLib.js, que básicamente son dos:
- Recoger el valor de volumen máximo en dB de un vídeo.
- Aumentar el volumen del audio de un vídeo en la cantidad indicada.
Si ya no lo recuerdas, correspondía a las llamadas de estas dos funciones:
ffmpeg -i INPUT.mp4 -af "volumedetect" -f null /dev/null
ffmpeg -i INPUT.mp4 -af "volume=10.7dB" -strict -2 INPUT_NORMALIZED.mp4
Para modelarlas vamos a utilizar dos métodos diferentes:
- Usando el wrapper fluent-ffmpeg para manejar FFMpeg desde NodeJS.
- Utilizando la capacidad de NodeJS para lanzar comandos.
Vamos con ello:
4.3.3. Fluent-FFMpeg y Testing de Asincronía.
Se trata de un módulo de NodeJS para poder manejar FFMpeg de una forma amigable. Se puede encontrar en https://github.com/fluent-ffmpeg/node-fluent-ffmpeg. Se instala como una dependencia más. Si recuerdas, la hemos instalado al comienzo.
Es fácil de utilizar, como todo en nodeJS:
var ffmpeg = require('fluent-ffmpeg');
El principal problema que nos encontramos es la asincronía de las operaciones. Es decir, como son operaciones de proceso y Javascript es asíncrono, el resultado no se obtiene al final del proceso, sino que se obtiene en un callback al que llama la función cuando acaba. Lo vemos mejor en código:
El código Javascript usando Fluent-FFMpeg para la llamada:
ffmpeg -i INPUT.mp4 -af "volumedetect" -f null /dev/null
es el siguiente:
var getMaxdBFromFile = function(pathTofile, callback){
var command = ffmpeg(pathTofile)
.withAudioFilter('volumedetect')
.addOption('-f', 'null')
.on('start', function(commandLine) {
console.log('FFmpeg Command:' + commandLine);
})
.on('error', function(err, stdout, stderr) {
console.log('An error occurred: ' + err.message);
})
.on('end', function(stdout, stderr){
var returnedText = utils.getMaxDbFromText(stderr);
callback(returnedText)
})
.saveToFile('/dev/null')
}
exports.getMaxdBFromFile = getMaxdBFromFile;
Si te fijas en la parte de configuración de callbacks, hay 3: start, error y end, que son llamadas para cada evento. El resultado queda en la parte de on:
.on('end', function(stdout, stderr){
var returnedText = utils.getMaxDbFromText(stderr);
callback(returnedText);
})
}
Básicamente lo que se ha programado son dos cosas:
- Coger el texto de la salida que se muestra con el resultado (esta librería lo deja en sterr) y se pasa por la función de utilidades que es capaz de extraer sólo la información de los dB de volumen máximo.
- Pasarle el valor ya filtrado a una función de callback que operará con ello.
Esta función de callback es fundamental, tanto para el desarrollo del programa como para el test oportuno. Por eso hemos puesto el código primero, para demostrar cómo se trata la asincronía con Mocha.
Si intentamos hacer un assert de Chai llamando a la función, fallará al instante porque Mocha, al ejecutar el código Javascript, llama a la función y continúa la ejecución: no espera a que el proceso asíncrono se ejecute.
Afortunadamente Mocha cuenta con un mecanismo para tratar la asincronía. Vamos a hacer el test.
Accedemos al fichero audioLibTest.js en el directorio test para hacer el test de integración sobre un fichero. A este fichero ya le hemos pasado el ffmpeg manualmente, así que sabemos ya el resultado.
Para tratar la asincronía hacemos uso del apartado “before” dentro de un describe, que tiene que ejecutarse antes de los “it” de Mocha. Además, el before, recibe por parámetro la función reservada “done()” de Mocha, que asegura que esperará a que se termine de ejecutar.
Básicamente lo que hacemos es llamar a la función a testear dentro del “before”, y además incluimos en la llamada una función de callback, preparando una variable “resultText” que es la que se evaluará en los asserts posteriores. Este es el código final:
var audioLib = require('../libs/audioLib');
var utils = require('../libs/utils');
var chai = require('chai');
var DIR = './test/';
var VIDEO_FILE = 'SampleVideo_1080x720_1mb.mp4';
var VIDEO_EXTENSION = 'mp4';
describe('Use of FFMpeg to get Max Volume', function() {
var resultText;
before(function(done){
audioLib.getMaxdBFromFile(DIR + VIDEO_FILE, function(text){resultText = text;done();});
});
it("Should get max_volume correct value for a specific video file using ffmpeg", function(){
chai.assert.include(resultText, "-10.7", "Max Volume found");
});
});
Como se puede ver, la función callback se limita a recoger el resultado y dejarlo en una variable con un scope al que puedan acceder los asserts de chai. Además, incluye done(), que espera a que concluya el proceso asíncrono, de modo que cuando se ejecutan los bloques “it”, la variable “resultText” ya tiene el valor adecuado y puede ser evaluada.
Para el comando de variación del nivel de audio del vídeo vamos a hacer una llamada directamente al sistema con el módulo nativo de NodeJS “child_process”. Como usaremos la salida y la entrada estándar (stdin/stdout) -lo requiere ffmpeg-. Tenemos que usar la función spawn.
Del mismo modo que antes, se trata de una operación lenta y asíncrona por lo que el resultado se dará en un callback.
Para el comando:
ffmpeg -i INPUT.mp4 -af "volume=10.7dB" -strict -2 INPUT_NORMALIZED.mp4
Tendremos el siguiente código:
var spawn = require('child_process').spawn;
var utils = require('./utils.js');
var normaliceAudio = function(pathTofile,leveldB, callback){
var outputFile = utils.getVideoNameForNormalizado(pathTofile);
utils.deleteFileIfexists(outputFile);
var command = spawn('ffmpeg',['-i',pathTofile,'-af','volume='+leveldB+'dB','-strict','-2',outputFile]);
command.stdout.on('data', function (data) {
console.log('stdout: ' + data);
});
command.stderr.on('data', function (data) {
console.log('stderr: ' + data);
});
command.on('close', function (code) {
console.log('FFMpeg process exited with code ' + code);
callback();
});
}
exports.normaliceAudio = normaliceAudio;
Si observas, el require de “child_process” tiene un .spawn al final. Esto quiere decir que sólo se quiere importar la función “.spawn”.
Como antes, establecemos unos callback: para la salida estándar (stdout), para la salida de error (stderr) y para cuando se cierre el comando porque acaba (‘close’). De nuevo ponemos ahí la referencia a una función de callback que pasamos por parámetro para procesar.
El Test de integración para ver si ha funcionado es más enrevesado esta vez, porque tiene que procesar el fichero y para comprobar que lo ha hecho bien, tiene que volver a calcular el volumen máximo. ¿Cómo lo encadenamos? De nuevo a base de callbacks:
describe('Use of FFMpeg to get Normalize', function() {
var resultText;
before(function(done){
audioLib.normaliceAudio(DIR + VIDEO_FILE, "10.7", function(text){
audioLib.getMaxdBFromFile(utils.getVideoNameForNormalizado(DIR + VIDEO_FILE), function(text){
resultText = text;done();
});
});
});
it("Should obtain -0.0 db as max_volume after normalization of the video", function(){
chai.assert.include(resultText, "-0.0", "Max Volume found");
});
});
Si te fijas, ahora el callback es la llamada a la otra función y dentro se introduce de nuevo un callback para sacar el resultado de analizar el volumen máximo. Como los callback se ejecutan al finalizar las operaciones, no hay problemas de sincronización.
Y de nuevo la omnipresente función done(), que provoca que el “before” no termine hasta que se han ejecutado todas las funciones.
4.4. El módulo final
Ya tenemos todas las funciones testeadas y con los test correctos, incluidos los de integración. Ahora queda juntar todo en un módulo principal que pueda ejecutar NodeJS y que contenga las llamadas a los módulos que acabamos de crear.
Básicamente, lo que tiene que hacer es:
- Obtener el listado de los ficheros de la extensión indicada a procesar de un directorio.
- Calcular el volumen máximo del fichero.
- Alterar el fichero para subir el volumen.
Sacar el listado de ficheros es sencillo. Lo hemos hecho antes:
var videos = audioLib.getMp4Files(videoDir,videoExtension);
Para mayor utilidad, el directorio (videoDir) y la extensión (videoExtension) las hemos sacado de los parámetros al llamar a la ejecución del fichero con:
node audioNormalizer.js directorio extension
var videoDir = process.argv[2];
var videoExtension = process.argv[3];
El valor 2 y 3 corresponden al parámetro número 3 y 4 de la llamada node. El 0 corresponde a node y el 1 corresponde a audioNormalizer.js.
Una vez tenemos todos los ficheros los recorremos con un bucle y llamamos a las otras dos funciones. Pero ahora veremos que no es tan sencillo.
Como hemos dicho, las funciones de audioLib getMaxdBFromFile y normaliceAudio son funciones que tienen llamadas asíncronas, y por tanto, una vez invocadas, devuelve rápidamente el control al flujo del programa, lanzándose asíncronamente sus procesos y devolviendo en un callback el resultado. ¿Cómo afecta esto al recorrer el array de ficheros de vídeos? De una manera no deseada: se lanzan todos los procesos de cada vídeo en paralelo. Si son 2 o 3 puede ser hasta bueno (aunque FFMpeg hace un muy buen uso de los multiprocesos). Pero si son más, es claramente ineficiente y puede bloquear el ordenador en el que lo estamos ejecutando.
Como hemos visto al hacer los test de integración de cada una de las partes, la clave está en las funciones de Callback. Estas funciones son las que recogen el resultado y aseguran que tenemos un punto en el código en el que hay certeza de que la operación asíncrona lanzada ha finalizado. Así pues tenemos este esquema:
- Llamada a getMaxdBFromFile para obtener el volumen máximo del vídeo.
- Callback que recoge el valor y llama a normalizeAudio.
- Callback sobre el resultado para encolar el siguiente vídeo de la lista, aumentando un contador y volviendo a llamar al proceso.
Sí, estamos haciendo uso de la recursividad. En vez de un bucle o una instrucción map sobre un array, lo que vamos a hacer es mantener un índice que indica sobre qué video del array de vídeos se va a operar. Este índice se altera dentro del callback final, que además vuelve a llamar a la función que lo engloba todo. Lo veremos mejor en el código:
var counter = 0;
var loopProcessVideos = function(videos, counter){
if (counter" + dB);
audioLib.normaliceAudio(videoDir + videos[counter].toString(),audioLib.reverseSign(dB),function(){
console.timeEnd("Main");
loopProcessVideos(videos,++counter);
} )
});
}
};
loopProcessVideos(videos,0);
Podemos ver el contador, que se inicializa a 0 para comenzar con el primer vídeo del array. La última instrucción es la llamada inicial a la función recursiva, loopProcessVideos(videos,0) y que desencadena todo el proceso.
Y entre ambos está la definición de la función recursiva. ¿Cómo sabemos que es recursiva? Fácil: tiene dos condicionantes. En primer lugar la condición de parada:
if (counter
De otro modo estaría ejecutándose de forma infinita. Esta condición comprueba que el índice no se salga del vector. Es decir, que cuando llegue al último finalice el proceso.
Y también:
loopProcessVideos(videos,++counter);
Que no es otra cosa que la llamada recursiva de nuevo a la propia función pero aumentando un número más el valor el contador o puntero a los vídeos para que procese el siguiente.
Como se puede ver, a través del uso de callbacks y una estructura recursiva, hemos eliminado los problemas de asincronía que surgen si se emplean estructuras que están preparadas únicamente para mecanismos síncronos. Es cierto que también existen otros modos de tratar los problemas de sincronización, como por ejemplo la librería async, pero lo dejamos para otros tutoriales..
5. Ejecución
No he incorporado todo el código en este tutorial porque sería demasiado extenso. Pero puedes hacerte un fork del repositorio de gitHub en el que he alojado la versión final y probarlo por ti mismo (y mejorarlo y adaptarlo a tus necesidades). Lo puedes descargar con:
git clone https://github.com/4lberto/VideoAudioNormalizer
Tampoco olvides descargar las dependencias. Ejecutando este comando en el directorio raíz:
npm install
Y como aparece en el README.md la ejecución es muy sencilla, siempre que tengas instalados los requisitos:
node audioNormalizer.js directorio extension
Por ejemplo:
node audioNormalizer.js /home/4lberto/Video mp4
Pero como somos desarrolladores, y hemos empleado tests para el desarrollo, te recomiendo que lo primero que hagas sea pasar los test con Mocha y veas que todo funciona correctamente (espero). Incluso he incorporado un sencillo fichero .mp4 en el directorio test para poder ejecutar los test de integración.
Simplemente ejecutamos:
mocha
Deberíamos obtener una salida como la siguiente:
✓ Should obtain -0.0 db as max_volume after normalization of the video
getFilesFromDirWithExtension
✓ Should get more than 0 files from the dir
✓ Should return only .mp4 files
textUtils
✓ Should get value for max volume for 1 integer and 1 decimal
✓ Should get value for max volume for 2 integer and 1 decimal
✓ Should get value for max volume for 4 integer and 1 decimal
✓ Should return the reverse sign of value obtained
✓ Should return the positive value obtained
✓ Should return the normalizado Filename
11 passing (2s)
En realidad no están todos los 11 test porque antes de este texto aparecen las trazas del procesamiento de FFMpeg y sería demasiado extenso como para ponerlo aquí.
6.Conclusiones
Hemos utilizado la excusa de la normalización de audio de los vídeos para explorar el mundo de NodeJS y sus particularidades. Como todo buen inicio en una nueva tecnología de programación, se debe comenzar creando un entorno en el que se puedan ejecutar tests para guiar nuestro desarrollo, para lo cual hemos incluido Mocha y Chai. Se ha revisado el sistema de módulos de NodeJS para compartimentar las aplicaciones. También hemos visto las particularidades de NodeJS con los procesos asíncronos, y cómo se pueden testear a través de callbacks y la función done() de Mocha.
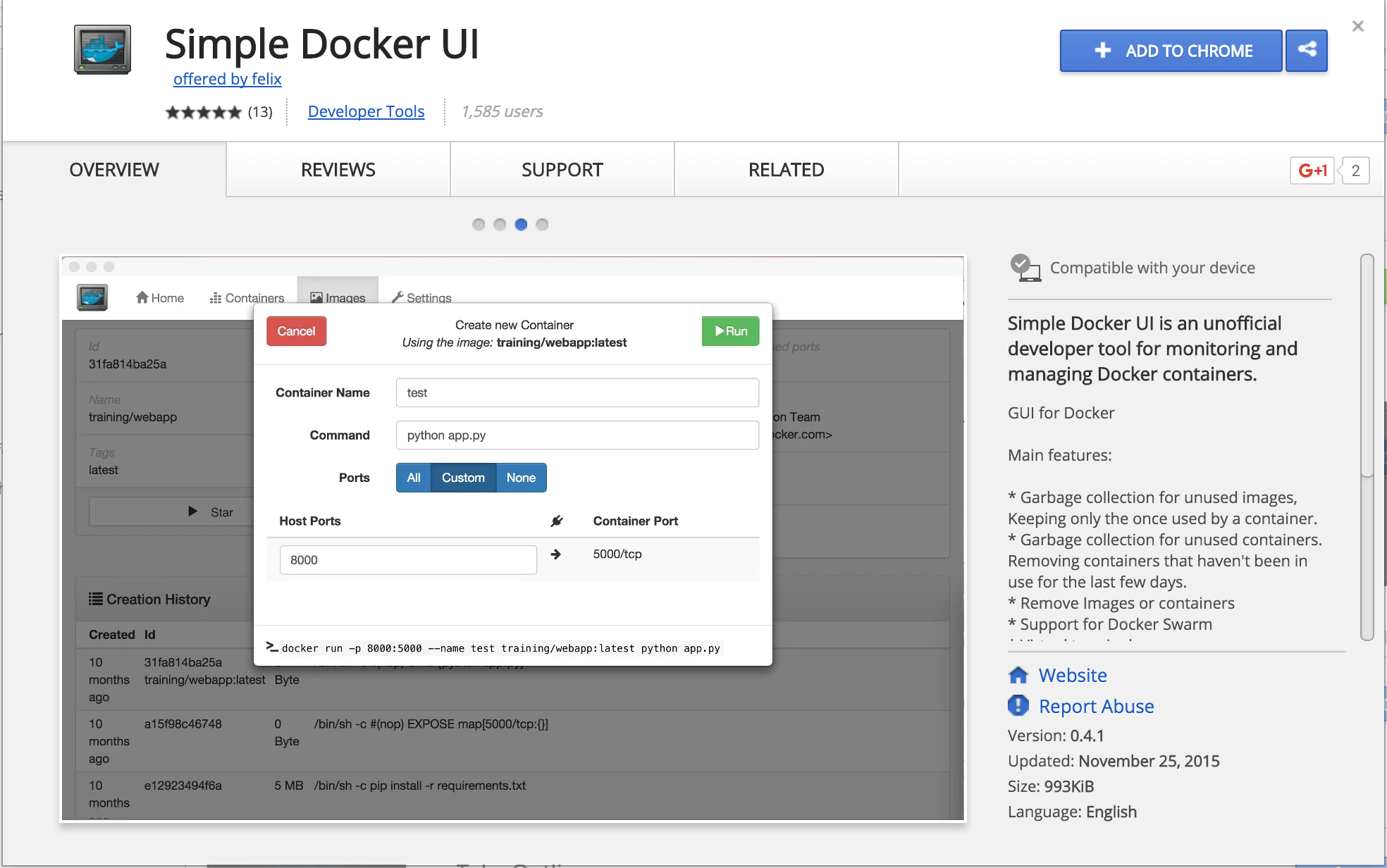
 .
Como estamos viendo en esta serie de tutoriales, el ecosistema Docker y todas las
herramientas que surgen a su alrededor, están creciendo a un ritmo imparable .. apenas hemos rascado en las posibilidades que nos ofrece esta tecnología, seguiremos en ello…
.
Como estamos viendo en esta serie de tutoriales, el ecosistema Docker y todas las
herramientas que surgen a su alrededor, están creciendo a un ritmo imparable .. apenas hemos rascado en las posibilidades que nos ofrece esta tecnología, seguiremos en ello…