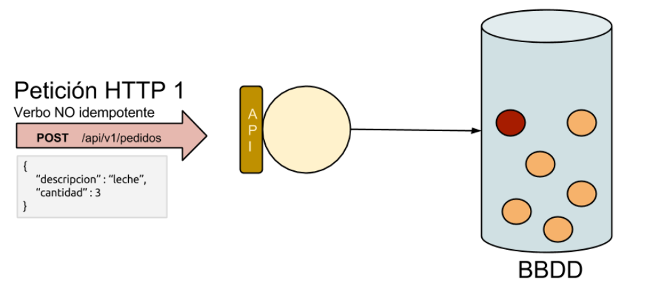
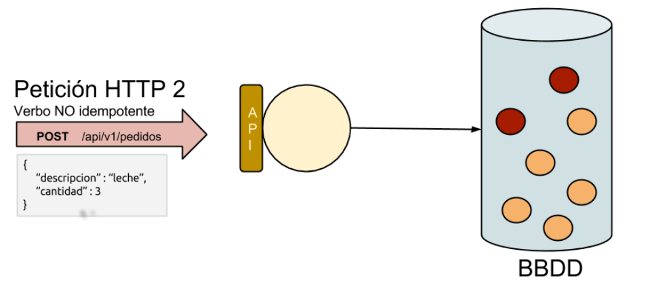
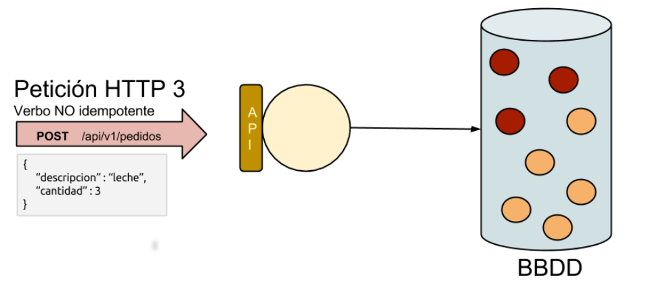
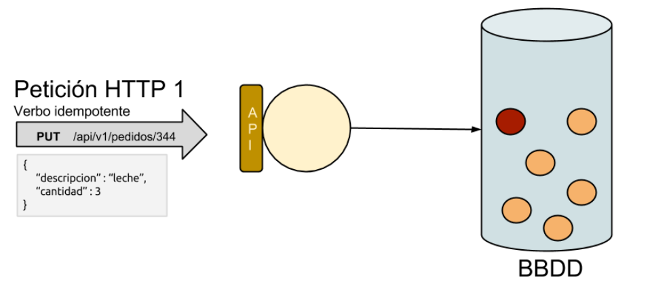
0. Índice de contenidos.
- 1. Introducción
- 2. Entorno
- 3. Instalación y arranque del servidor
- 4. Configuración proyecto
- 5. Implementación de Emisor y Receptor
- 6. Visualización de resultados
- 7. Conclusión
1. Introducción.
En este tutorial se va a mostrar como implementar un emisor y un receptor que utilicen el protocolo AMQP (Advanced Message Queuing Protocol). Para ello vamos a utilizar el servidor de intercambio RabbitMQ. Se trata de un servidor open source que implementa el protocolo AMQP, escrito en Erlang y construido sobre el framework Open Telecom Platform (OTP). La versiones utilizadas en este tutorial son:- JDK 1.8.0_40
- Servidor RabbitMQ para mac v3.5.3.
- Cliente RabbitMQ v3.5.3
2. Entorno.
El tutorial está escrito usando el siguiente entorno:- Hardware: MacBook Pro 17′ (2.66 GHz Intel Core i7, 8GB DDR3 SDRAM).
- Sistema Operativo: Mac OS X Lion 10.10.3.
- NVIDIA GeForce 330M 512Mb.
- Crucial MX100 SSD 512 Gb.
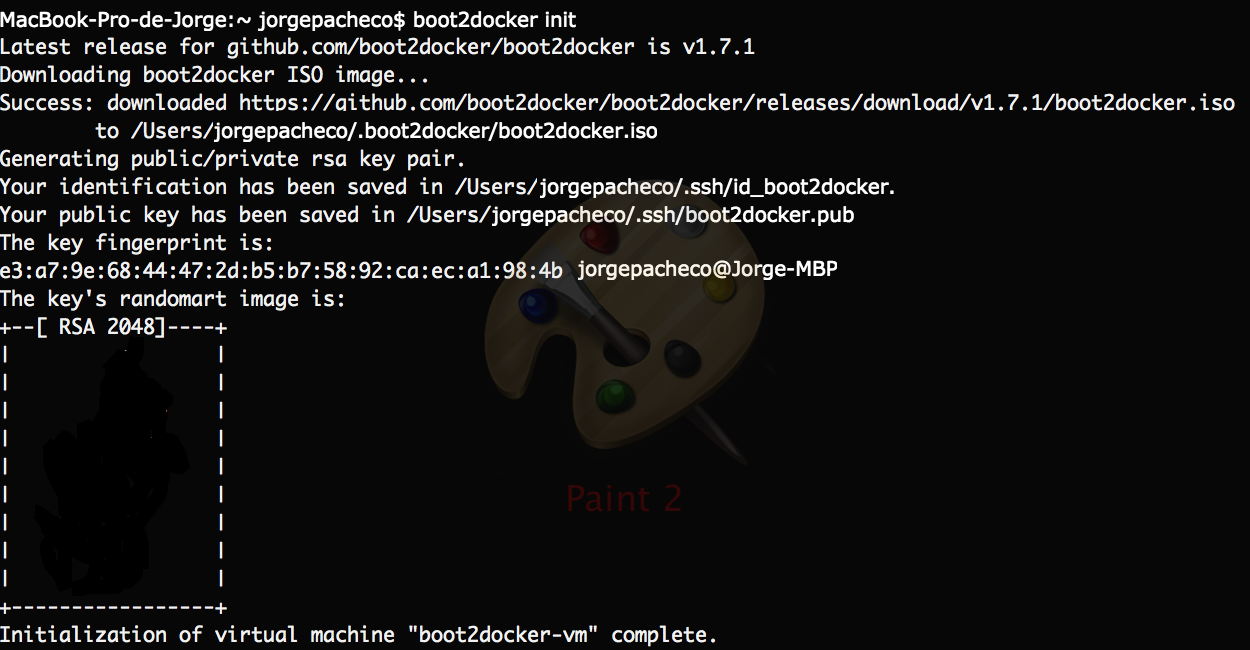
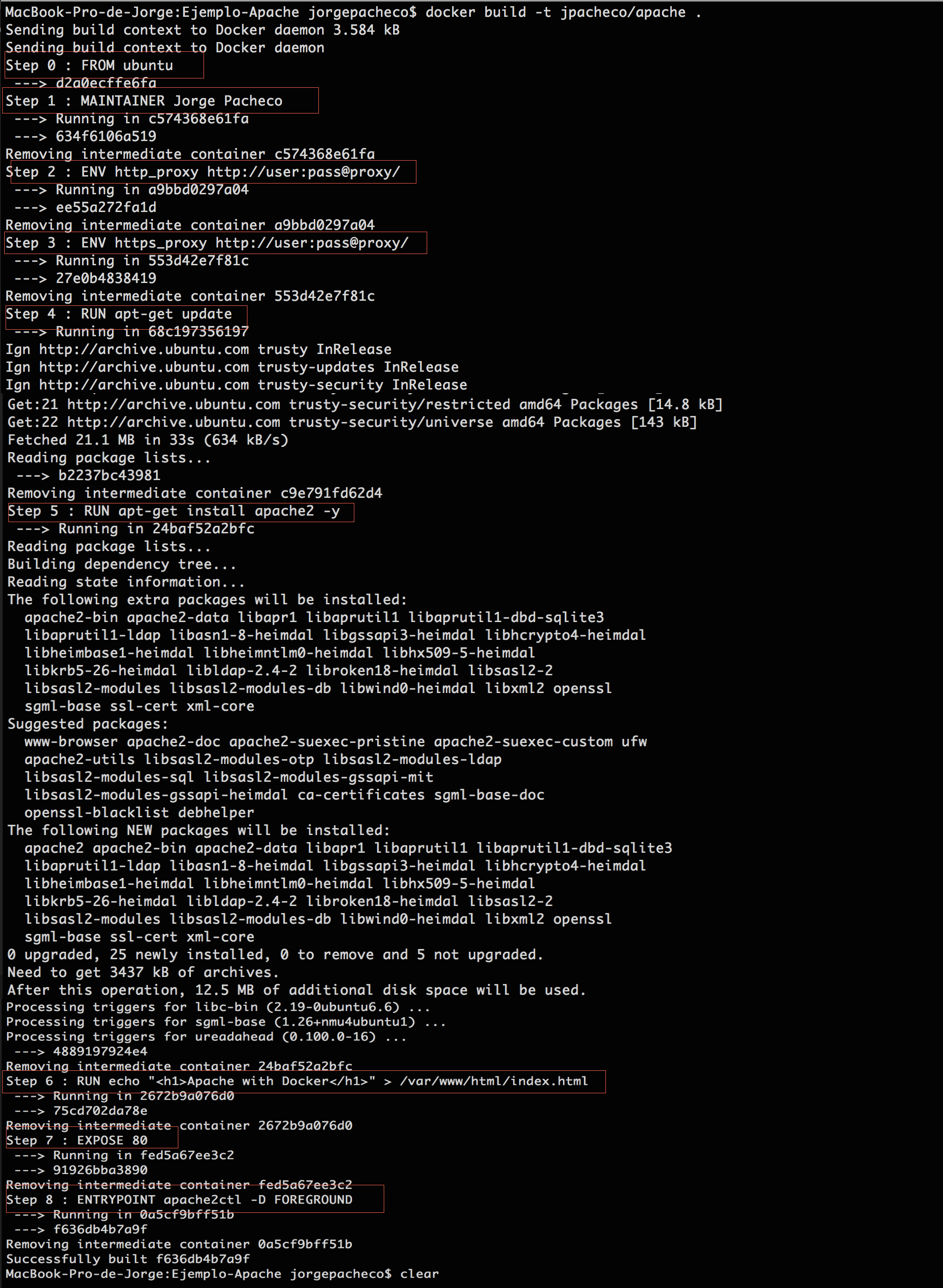
3. Instalación y arranque del servidor.
Lo primero que tenemos que hacer es descargarnos el servidor desde la página oficial desde este enlace.
A continuación procedemos con la descompresión del contenido del fichero en la ruta que nos convenga, en mi caso:
/Users/jrodriguez/rabbitmq-server
Para el caso que vamos a ver en este tutorial no necesitamos configurar el servidor, así que podemos arrancar el servidor de intercambio dirigiendonos a la carpeta “sbin” de la instalación del servidor y ejecutando el shell script “rabbitmq-server”.
4. Configuración proyecto.
Abrimos nuestro IDE, en mi caso Eclipse Luna, y procedemos con la creación de un nuevo proyecto Maven. Existen multiples tutoriales, en AdictosAlTrabajo, en los que explicamos como crear un proyecto Maven.
Una vez creado el proyecto, y para finalizar la configuración, agregamos dentro del fichero pom.xml la dependencia del cliente de RabbitMQ:
com.rabbitmq amqp-client 3.5.3
5. Implementación de Emisor y Receptor.
5.1 Emisor
Agregamos una clase al proyecto llamada Emisor con el siguiente contenido:
package com.rabbitmq.basic;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class Emisor {
private final static String QUEUE_NAME = "MAIN_QUEUE";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "¡Hola!";
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Enviar '" + message + "'");
}
}
Vamos a dividir el código anterior en dos partes para explicar qué hace.
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
Por un lado tenemos el establecimiento de la conexión y del canal de comunicaciones. Para ello hacemos uso de una factoría de conexiones, establecemos el Host, generamos una nueva conexión y creamos un nuevo canal de comunicaciones a través de la conexión.
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "¡Hola!";
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Enviar '" + message + "'");
Por otro lado, establecemos las propiedades del canal y lo utilizamos para publicar un mensaje en el mismo.
5.2 Receptor
Agregamos una clase al proyecto llamada Receptor con el siguiente contenido:
package com.rabbitmq.prueba2;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.ConsumerCancelledException;
import com.rabbitmq.client.QueueingConsumer;
import com.rabbitmq.client.ShutdownSignalException;
public class Receive {
private final static String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException,
TimeoutException, ShutdownSignalException,
ConsumerCancelledException, InterruptedException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] A la espera de mensajes. Para salir pulse: CTRL+C");
QueueingConsumer consumer = new QueueingConsumer(channel);
channel.basicConsume(QUEUE_NAME, true, consumer);
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [x] Recibido: '" + message + "'");
doWork(message);
System.out.println(" [x] Hecho!!! ");
}
}
private static void doWork(String task) throws InterruptedException {
Thread.sleep(8000);
}
}
Como en el caso del amos a dividir el código anterior en 3 partes para explicar qué hace.
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
Como en el caso anterior, en la primera sección de código tenemos el establecimiento de la conexión y del canal de comunicaciones.
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] A la espera de mensajes. Para salir pulse: CTRL+C");
QueueingConsumer consumer = new QueueingConsumer(channel);
channel.basicConsume(QUEUE_NAME, true, consumer);
A continuación, configuramos el canal de comunicaciones e instanciamos un consumidor que va a ser el encargado de obtener la información del canal.
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [x] Recibido: '" + message + "'");
doWork(message);
System.out.println(" [x] Hecho!!! ");
}
Para finalizar establecemos un bucle que se encargue de estar a la escucha, constantemente, de mensajes enviados al canal. Hemos introducido un método “doWork” que simplemente emula tareas internas del hilo.
6. Visualización de resultados.
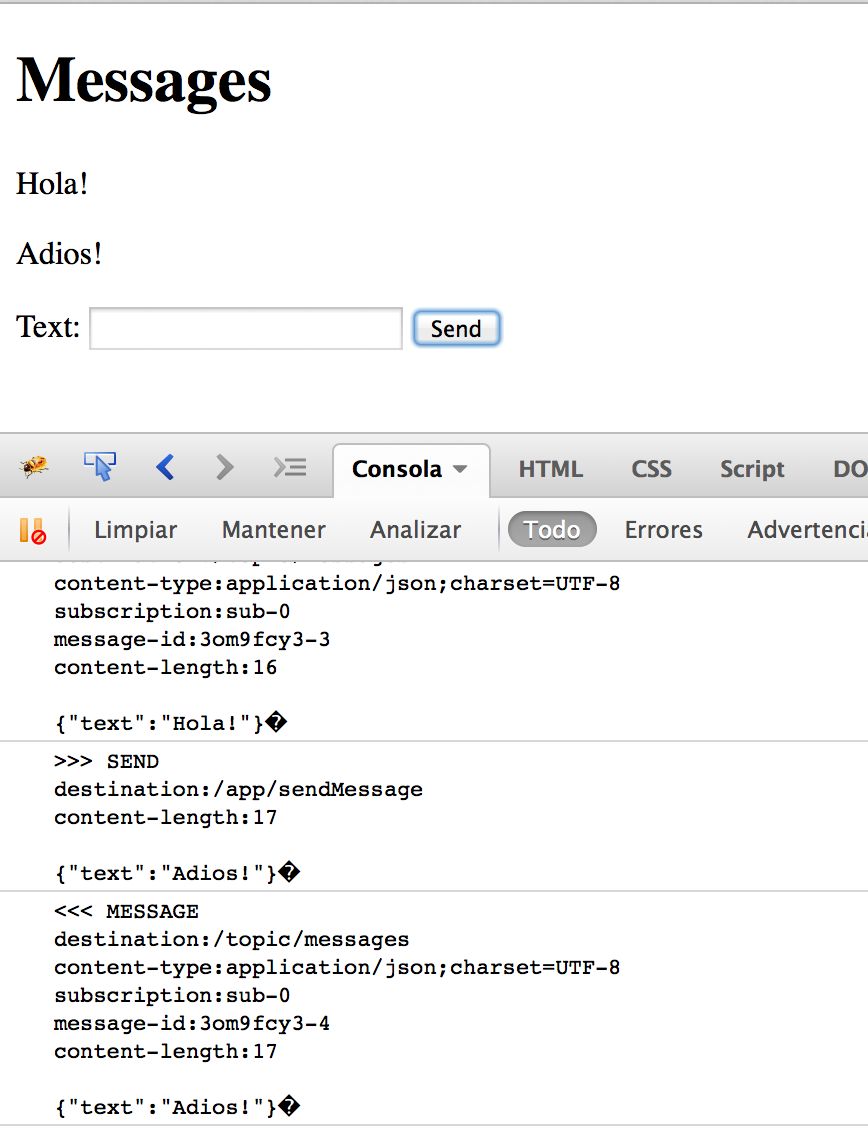
Basta con lanzar cada uno de los ejecutables (el emisor en varias ocasiones), mientras el servidor intermediario se encuentra en ejecución para observar el proceso de comunicación entre los emisores y el receptor.











 .
.