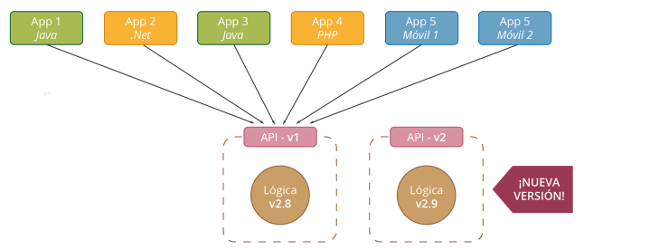
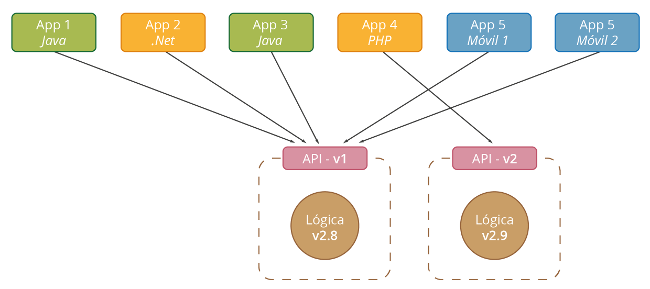
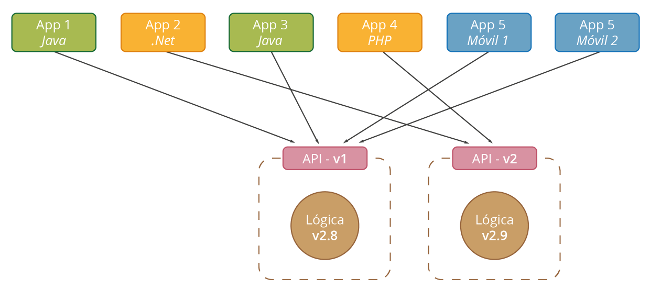
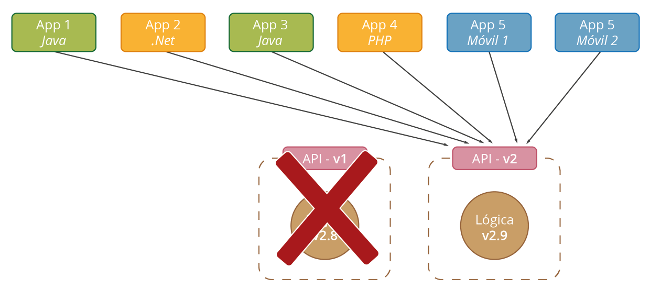
En este tutorial veremos como crear un entorno de integración utilizando las herramientas Ansible para automatizar tareas y Vagrant como proveedor de máquinas virtuales.
0. Índice de contenidos
1. Introducción
La mayoría de proyectos necesitan de un entorno de integración continua en el cual podemos ver y detectar los fallos de forma temprana, sin llegar al entorno de producción. Este tutorial pretende crear una plantilla de entorno de integración de modo que puedas desplegar de forma sencilla un entorno de integración continua gracias a la gran combinación de vagrant y ansible.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro Retina (2.93 Ghz Intel Core 2 Duo, 8GB DDR3).
- Sistema Operativo: Mac OS Yosemite 10.10
- Virtual Box
- Vagrant 1.7.2
- Ansible 1.9.2
3. Instalación de requisitos
Para preparar el entorno de integración continua, crearemos la máquina virtual con Vagrant, un generador de máquinas virtuales a partir de imágenes previamente construidas (boxes). La plataforma en la que estará nuestra máquina virtual será Virtual Box y para configurar la máquina e instalar el software necesario utilizaremos ansible, que automatiza las tareas y despliega de forma sencilla, de modo que pueda replicarse en cualquier máquina remota.
3.1. Instalación de Virtual Box
Nos descargamos Virtual Box desde aquí, seleccionamos el paquete que necesitemos dependiendo de nuestro sistema operativo, y seguimos las instrucciones del instalador.
3.2. Instalación de Vagrant
Obtenemos Vagrant desde su página de descarga donde seguimos igualmente el proceso de descarga que requiera nuestro sistema operativo.
Para comprobar que lo tenemos correctamente instalado, ejecutamos por línea de comandos:
vagrant --version
3.3. Instalación de Ansible
Las instrucciones de descarga de ansible pueden ser encontradas aquí.
La instalación recomendada es vía pip, el gestor de paquetes de Python. Si no lo tenemos instalado debemos instalar pip primero y luego instalar Ansible.
sudo easy_install pip
pip --version
pip 6.1.1 from /Library/Python/2.7/site-packages/pip-6.1.1-py2.7.egg (python 2.7)
sudo pip install ansible
ansible --version
ansible 1.9.2
4. Creación y configuración de la máquina virtual
Una vez instalados Vagrant y Ansible, estamos preparados para crear la máquina virtual de pruebas de nuestro entorno de integración, y configurarla para que nuestras aplicaciones funcionen detrás de un apache que hace de proxy interno.
4.1. Elección del box de Vagrant
Para crear la configuración de la máquina virtual creamos el directorio en el cual queramos tener la configuración de la máquina virtual, y después le decimos a vagrant que se descarge la imagen (box) con la que queremos que esté contruida nuestra máquina virtual con el siguiente comando:
mkdir continuous_integration
vagrant box add ubuntu/trusty64
Vagrant ofrece una gran cantidad de boxes, así como la posibilidad de crear tus propias boxes personalizadas. Puedes encontrar boxes en el siguiente enlace.
4.2. Creación Vagrantfile
A continuación, para generar el fichero de configuración base de la máquina virtual usamos el comando:
vagrant init
Este comando crea el fichero de configuración que será leído cuando arranquemos o levantemos la máquina, y es donde especificaremos la box que va a utilizar vagrant para crear la máquina virtual, si disponemos de algún ‘provider’ para que instale software por defecto, así como configuración entre la máquina real y la máquina virtual. Tras ejecutar este comando, en la carpeta elegida para almacenar la configuración deberían tener la siguiente estructura:
![img1]()
Comprobamos que ha aparecido el fichero Vagrantfile, donde estableceremos la configuración de que imagen va a utilizar la máquina virtual, así como quien se va a encargar de instalar sofware en la misma. El fichero debería quedar de la siguiente manera:
Vagrantfile
Vagrant.configure(2) do |config|
config.vm.box = "ubuntu/trusty64"
#Fix SSH forwarded port
config.vm.network "forwarded_port", guest: 22, host:2222, id: "ssh", auto_correct: true
#Use Apache
config.vm.network "forwarded_port", guest: 80, host:8080, id: "apache", auto_correct: true
config.vm.define "continuous_integration" do |continuous_integration|
continuous_integration.vm.provision "ansible" do |ansible|
ansible.inventory_path = "ansible/environments/continuous_integration/inventory"
ansible.verbose = 'vvv'
ansible.playbook = "ansible/continuous_integration.yml"
end
config.vm.provider "virtualbox" do |v|
v.memory = 2048
end
end
end
A continuación analizamos el significado del siguiente fichero:
Vagrant.configure(2) do |config|
El “2” de la primera línea representa la versión del objeto de configuración config que será usado para la configuración del bloque.
config.vm.box = "ubuntu/trusty64"
Con la siguiente línea le indicamos a vagrant que box utilizará para la creación de la máquina virtual.
#Fix SSH forwarded port
config.vm.network "forwarded_port", guest: 22, host:2222, id: "ssh", auto_correct: true
#Use Apache
config.vm.network "forwarded_port", guest: 80, host:8080, id: "apache", auto_correct: true
La siguiente línea nos permite acceder a un puerto de nuestra máquina real (host) y que todos los datos sean redirigidos a la máquina virtual (guest) a través de un determinado puerto. La propiedad auto_correct:true indica que si hay un conficto debido a que ese puerto está actualmente en funcionamiento, vagrant se encargará de solucionarlo de forma automática cuando esté levantando la máquina virtual. Esto quiere decir que para poder acceder al apache de nuestra máquina virtual por un navegador, usaremos el puerto 8080 en nuestra máquina real (quitar esta opción si vamos a desplegar la aplicación en una máquina remota)
config.vm.define "continuous_integration" do |continuous_integration|
El uso de la propiedad define sirve para especificar un entorno dentro de la máquina de configuración (ya que vagrant permite la configuración de multiples máquinas virtuales en el mismo Vagrantfile). Nosotros definimos un entorno en el cual todas las propiedades que estén dentro del ámbito de este entorno, solo afectarán a esa única máquina sobreescribiendo las propiedades por defecto en caso de conflicto.
Nota: Dentro del ambito de define, “continuous_integration” es sinónimo de “config”.
continuous_integration.vm.provision "ansible" do |ansible|
Dentro del entorno de integración indicamos a la configuración de vagrant que trandrá un encargado de instalar el software a la hora de crear la máquina. En este caso, será ansible.
ansible.inventory_path = "ansible/environments/continuous_integration/inventory"
ansible.verbose = 'vvv'
ansible.playbook = "ansible/continuous_integration.yml"
Para que ansible se ejecute necesita dos ficheros clave: Uno es el inventory, donde se indicarán los grupos que tiene ansible, así como las ip que están dentro de cada uno de ellos.
El otro fichero necesario es el playbook, que contiene cuales son las tareas que ansible va a realizar, y en que grupos de host las va a realizar (previamente definidos en el inventory).
config.vm.provider "virtualbox" do |v|
v.memory = 2048
end
Como estamos realizando pruebas en una máquina virtual, le damos más memoria para que no haya problemas a la hora de levantar las aplicaciones.
4.3. Creación del inventory
Cuando usamos ansible, este necesita saber en qué máquinas debería correr un determinado playbook. La forma de indicarle estás máquinas es mediante el inventory. Vagrant tiene dos formas de crear este fichero, una de forma automática y otra de forma manual. Nosotros usaremos la forma manual, para lo cual rellenaremos el fichero con el siguiente contenido.
ansible/environments/continuous_integration/inventory
continuous_integration ansible_ssh_host=127.0.0.1 ansible_ssh_port=2222
[ci]
continuous_integration
-
En la primera línea especificamos el host de la máquina creada, y el puerto que habíamos establecido anteriormente que redireccionaba al puerto 22 de la máquina que va a ser creada. Esta información debe ser especificada tanto en el Vagrantfile como en el Inventory.
-
A continuación entre paréntesis tenemos el grupo de máquinas en el cual se ejecutará un determinado playbook. Esto quiere decir que si queremos que otra máquina ejecute estas tareas de ansible, a la hora de ejecutar el comando, solo tenemos que añadir aquí la ip de esa máquina y también ejecutará el mismo playbook.
-
Por último, indicamos las máquinas que estan dentro del grupo de máquinas. El nombre de las máquinas en el Vagrantfile y en el inventory deben ser iguales por defecto, de ahí que llamemos continuous_integration a nuestra máquina.
4.4. Uso de variables en las tareas de ansible
Durante la creación de los playbook usaremos un único lugar para establecer variables específicas, como el nombre a cambiar de un directorio creado con ansible, o una url de descarga, de forma que no tengamos que buscar dentro de los playbook, y evitar posibles errores humanos.
Para minimizar este riesgo usaremos variables que estarán localizadas en un directorio group_vars creado a la altura del inventoryque tendrá dentro un fichero con el nombre del grupo de hosts que estemos ejecutando (en nuestro caso se llamará ‘ci’) en el que guardaremos todas estas variables.
Las variables que utilizaremos en las tareas de los roles son:
environments/continuous_integration/group_vars/ci
---
maven:
download_url: http://ftp.cixug.es/apache/maven/maven-3/3.3.3/binaries/apache-maven-3.3.3-bin.tar.gz
file: apache-maven-3.3.3-bin.tar.gz
home: /opt/apache-maven-3.3.3
sonar:
download_url: http://downloads.sonarsource.com/sonarqube/sonarqube-5.1.1.zip
archive: sonar.zip
version_dir: sonarqube-5.1.1
home: /opt/sonar
jdbc_username: sonar
jdbc_password: sonarpwd
jenkins:
password: jenkinspwd
base_dir: /var/lib/jenkins
apt_key: https://jenkins-ci.org/debian/jenkins-ci.org.key
repo: deb http://pkg.jenkins-ci.org/debian binary/
plugins_url: http://updates.jenkins-ci.org/latest
nexus:
version: 2.11.3-01
download_url: http://www.sonatype.org/downloads/nexus-2.11.3-01-bundle.tar.gz
base_dir: /opt
home: /opt/nexus
data_dir: /home/nexus
apache:
server_name: dev.example
ssl_folder: /etc/apache2/ssl
certificate_file: /etc/apache2/ssl/dev.example.crt
certificate_key_file: /etc/apache2/ssl/dev.example.key
sonar_http: http://localhost:9000/sonar
nexus_http: http://localhost:8081/nexus
jenkins_http: http://localhost:8080/jenkins
custom_log_file: app_custom.log
error_log_file: app_error.log
custom_https_log: app_custom_https.log
error_https_log: app_error_https.log
Podemos agrupar las variables en grupos más generales.
Las variables tienen el formato nombre_variable: valor (El espacio es importante!!!) de modo que si quisieramos la variable version del grupo de variables nexus la llamaríamos de la siguiente forma en el playbook:
{{nexus.version}}
4.5. Creación del playbook
Ahora que ya tenemos definida las máquinas en las que se ejecutarán nuestras tareas de ansible, nos falta definir esas tareas. Esto se hace en el playbook, un documento YAML que define una serie de pasos que deben ser ejecutado en una o más máquinas.
Como de costumbre, escribiremos la estructura de nuestro playbook y luego explicaremos los datos más relevantes:
continuous_integration.yml
---
#file: continuous_integration.yml
- hosts: ci
sudo: yes
gather_facts: no
roles:
- common_os_setup
- dependencies
- java8
- sonar
- ansible
- jenkins
- maven
- nexus
- apache
Un playbook se estructura en “plays”. Estos son pequeñas divisiones que se van ejecutando en orden descendente.
-
La propiedad hosts indica cual es el grupo de máquinas en las cuales se ejecutaran las tareas de ansible, que coincide con el definido en nuestro inventory.
-
La propiedad sudo indica si se necesitan permisos de root para realizar algunas de las tareas.
-
gather_facts es información derivada de comunicarnos con nuestros sistemas remotos, como información sobre la dirección ip del host remoto, o que sistema operativo usa. En nuestro caso no nos comunicamos con ningún sistema remoto, por lo que esta opción está desabilitada.
-
La propiedad roles irá ejecutando las tareas de cada rol en orden descendente cuando se cargue el playbook. Las tareas podrían ir directamente en el playbook, pero de esta manera, es mucho más sencillo organizarlas por lo que hacen, así como tener separadas las responsabilidades por si en el futuro no necesitas realizar todas las tareas, sino reutilizar algunas antiguas y crear unas nuevas
![😉]()
4.6. Creación de Roles
Como ya hemos explicado anteriormente, los roles nos permiten organizar nuestras tareas. Crearemos el directorio roles en la cual estarán localizados todos los roles justo debajo de la carpeta ansible.
cd ansible
mkdir roles
Dentro de la carpeta roles la estructura es la siguiente:
-
roles/[nombre_rol]/tasks: Aquí dentro irá un fichero main.yml que contendrá las tareas de este rol.
-
roles/[nombre_rol]/handlers: Tendrá un fichero main.yml que contiene los handlers, que son respuestas a eventos que pueden cambiar el estado de las tareas. Los veremos más adelante.
-
roles/[nombre_rol]/templates: Dentro van las plantillas de los ficheros que se puede rellenar utilizando las variables declaradas anteriormente.
-
roles/[nombre_rol]/files: A direfencia de las plantillas, aquí pasamos el fichero tal cual, sin modificaciones de variables. Cuando necesitamos un fichero del host real, el mrol viene a buscarlo aquí por defecto.
Si no va a utilizar handlers, templates, o files no es necesario crearlas. Task suele ser la carpeta que está creada debido a que tiene las tareas a ejecutar por ansible.
Vamos a crear los roles definidos en el playbook comentando las partes más relevantes de cada uno.
4.6.1. common_os_setup
Este rol está encargado de realizar las tareas generales, como la descarga de paquetes de idiomas y asegurarse de que el sistema está actualizado.
roles/common_os_setup/tasks/main.yml
---
# file: roles/common_os_setup/tasks/main.yml
- name: ensure apt cache is up to date
apt: update_cache=yes
- name: ensure the language packs are installed
apt: name={{item}}
with_items:
- language-pack-en
- language-pack-es
- name: reconfigure locales
command: sudo update-locale LANG=en_US.UTF-8 LC_ADDRESS=es_ES.UTF-8 LC_COLLATE=es_ES.UTF-8 LC_CTYPE=es_ES.UTF-8 LC_MONETARY=es_ES.UTF-8 LC_MEASUREMENT=es_ES.UTF-8 LC_NUMERIC=es_ES.UTF-8 LC_PAPER=es_ES.UTF-8 LC_TELEPHONE=es_ES.UTF-8 LC_TIME=es_ES.UTF-8
- name: ensure apt packages are upgraded
apt: upgrade=yes
Cada tarea diferente comienza con un guión (-) y luego tiene una serie de propiedades. La propiedad name indica de forma intuitiva que hace cada tarea. En nuestro caso, tenemos 4 tareas, en las que hay que destacar:
- En la primera tarea usamos el módulo apt, que maneja los paquetes apt siendo esta linea equivalente al comando apt-get update.
- En la segunda tarea, usamos el mismo módulo, pero con la propiedad name. Esta propiedad indica el nombre del paquete a instalar, pero también permite el uso de variables. Ansible posee internamente la variable item (las variables van rodeadas de dobles corchetes {{variable}}) que indica que esa operación debe realizarse tantas veces como items haya dentro de la propiedad with_items. En este caso, equivale a los comandos:
apt-get language-pack-en
apt-get language-pack-es
Nota: En la documentación de ansible posees una lista de todos los módulos, así como las propiedades de cada uno.
Ansible también permite el uso de comandos de forma esplícita, como es el caso de la tercera tarea, donde se le dice que ejecute el comando descrito, encargado de actualizar los idiomas.
4.6.2. dependencies
Este rol se encarga de incluir dependencias que podrías necesitar en un entorno de integración continua.
roles/dependencies/tasks/main.yml
---
#file: /roles/dependencies/tasks/main.yml
- name: install unzip command
apt: name=unzip state=present
tags: dependency
- name: install git
apt: name=git state=present
tags: git
La propiedad: tag es muy útil durante el testing de tareas. Al especificar que que quieres correr un determinado playbook con una serie de roles, pero solo quieres probar lo último que has añadido, o un grupo determinado de tareas específicas, cuando corra la ejecución de ansible, puedes especificarle que solo ejecute las tareas con un tag determinado.
4.6.3. java8
Este rol se encarga de instalar java en la máquina remota.
roles/java8/tasks/main.yml
---
# file: /roles/java8/tasks/main.yml
- name: add Java repository to sources
apt_repository: repo='ppa:webupd8team/java'
tags: java
- name: autoaccept license for Java
debconf: name='oracle-java8-installer' question='shared/accepted-oracle-license-v1-1' value='true' vtype='select'
tags: java
- name: update APT package cache
apt: update_cache=yes
tags: java
- name: install Java 8
apt: name=oracle-java8-installer state=latest install_recommends=yes
tags: java
- name: set default environment variable
apt: name=oracle-java8-set-default
tags: java
Los dos módulos a destacar en este rol son:
-
apt-repository: que sirve para añadir o eliminar repositorios apt en ubuntu y debian.
-
debconf se encarga de configurar un paquete, en este caso para autoaceptar la licencia de java.
4.6.4. sonar
Este rol es el encargado de instalar y configurar sonar, que nos permite controlar y supervisar la calidad del código.
roles/sonar/tasks/main.yml
---
# file: /roles/sonar/tasks/main.yml
- name: download sonar
get_url: url="{{sonar.download_url}}" dest="/tmp/{{sonar.archive}}"
tags: sonar
- name: create sonar group
group: name=sonar state=present
tags: sonar
- name: create sonar user
user: name=sonar comment="Sonar" group=sonar
tags: sonar
- name: extract sonar
unarchive: src="/tmp/{{sonar.archive}}" dest=/opt copy=no
tags: sonar
- name: move sonar to its right place
shell: mv /opt/{{sonar.version_dir}} {{sonar.home}} chdir=/opt
tags: sonar
- name: change ownership of sonar dir
file: path="{{sonar.home}}" owner=sonar group=sonar recurse=yes
tags: sonar
- name: copy sonar properties
template: src=sonar.properties dest="{{sonar.home}}/conf/sonar.properties"
tags: sonar
- name: make sonar runned by sonar user
replace: dest="{{sonar.home}}/bin/linux-x86-64/sonar.sh" regexp="#RUN_AS_USER=(.*)$" replace="RUN_AS_USER=sonar"
tags: sonar
- name: add sonar links for service management
file: src="{{sonar.home}}/bin/linux-x86-64/sonar.sh" dest="{{item}}" state=link
with_items:
- /usr/bin/sonar
- /etc/init.d/sonar
tags: sonar
- name: ensure sonar is running and enabled as service
service: name=sonar state=restarted enabled=yes
tags: sonar
Este rol tiene chichilla ![😀]() vamos a analizarlo detenidamente:
vamos a analizarlo detenidamente:
-
En la primera tarea, vemos como nos descargamos sonar, pero en este caso desde una url con el módulo get_url. Este módulo tiene dos parametros obligatorios: url, que indica el lugar desde donde descargaremos el archivo y dest que es el lugar donde lo almacenaremos. La segunda cosa a destacar es que estamos usando variables para decirle cual es la url de descarga, así como el nombre del archivo descargado, localizadas en el fichero ci descrito al final del punto anterior.
- Con los módulos group y user, somos capaces de crear grupos y usuarios respectivamente.
- El módulo unarchive permite desempaquetar un archivo , y la opción copy=no indica que este archivo ya se encuentra en la máquina remota, y que no necesita ser copiado desde el host.
- El módulo shell es igual que el módulo visto previamente para realizar comandos.
- El módulo file nos permite crear directorios, así como estableces sus grupos, usuarios o permisos.
- La propiedad template en la tarea con el nombre copy sonar properties indica que el archivo mencionado va a ser recogido desde la carpeta templates localizada justo dentro del rol. En esta carpeta podremos introducir nuestras plantillas que pueden utilizar las variables de ansible, y serán rellenadas en el momento en el que las llames. El contenido de la plantilla es:
roles/sonar/templates/sonar.properties
# This file must contain only ISO 8859-1 characters.
# See http://docs.oracle.com/javase/1.5.0/docs/api/java/util/Properties.html#load(java.io.InputStream)
#
# Property values can:
# - reference an environment variable, for example sonar.jdbc.url= ${env:SONAR_JDBC_URL}
# - be encrypted. See http://docs.codehaus.org/display/SONAR/Settings+Encryption
#--------------------------------------------------------------------------------------------------
# DATABASE
#
# IMPORTANT: the embedded H2 database is used by default. It is recommended for tests but not for
# production use. Supported databases are MySQL, Oracle, PostgreSQL and Microsoft SQLServer.
# User credentials.
# Permissions to create tables, indices and triggers must be granted to JDBC user.
# The schema must be created first.
sonar.jdbc.username={{sonar.jdbc_username}}
sonar.jdbc.password={{sonar.jdbc_password}}
#----- Embedded Database (default)
# It does not accept connections from remote hosts, so the
# server and the analyzers must be executed on the same host.
sonar.jdbc.url=jdbc:h2:tcp://localhost:9092/sonar
# H2 embedded database server listening port, defaults to 9092
sonar.embeddedDatabase.port=9092
#----- MySQL 5.x
#sonar.jdbc.url=jdbc:mysql://localhost:3306/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useConfigs=maxPerformance
#----- Oracle 10g/11g
# - Only thin client is supported
# - Only versions 11.2.* of Oracle JDBC driver are supported, even if connecting to lower Oracle versions.
# - The JDBC driver must be copied into the directory extensions/jdbc-driver/oracle/
# - If you need to set the schema, please refer to http://jira.codehaus.org/browse/SONAR-5000
#sonar.jdbc.url=jdbc:oracle:thin:@localhost/XE
#----- PostgreSQL 8.x/9.x
# If you don't use the schema named "public", please refer to http://jira.codehaus.org/browse/SONAR-5000
#----- Microsoft SQLServer 2005/2008
# Only the distributed jTDS driver is supported.
#sonar.jdbc.url=jdbc:jtds:sqlserver://localhost/sonar;SelectMethod=Cursor
#----- Connection pool settings
sonar.jdbc.maxActive=20
sonar.jdbc.maxIdle=5
sonar.jdbc.minIdle=2
sonar.jdbc.maxWait=5000
sonar.jdbc.minEvictableIdleTimeMillis=600000
sonar.jdbc.timeBetweenEvictionRunsMillis=30000
#--------------------------------------------------------------------------------------------------
# WEB SERVER
# Web server is executed in a dedicated Java process. By default its heap size is 768Mb.
# Use the following property to customize JVM options. Enabling the HotSpot Server VM
# mode (-server) is recommended.
# Note that the option -Dfile.encoding=UTF-8 is mandatory.
#sonar.web.javaOpts=-Xmx768m -XX:MaxPermSize=160m -XX:+HeapDumpOnOutOfMemoryError \
# -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djruby.management.enabled=false
# Binding IP address. For servers with more than one IP address, this property specifies which
# address will be used for listening on the specified ports.
# By default, ports will be used on all IP addresses associated with the server.
#sonar.web.host=0.0.0.0
# Web context. When set, it must start with forward slash (for example /sonarqube).
# The default value is root context (empty value).
sonar.web.context=/sonar
# TCP port for incoming HTTP connections. Disabled when value is -1.
sonar.web.port=9000
# TCP port for incoming HTTPS connections. Disabled when value is -1 (default).
#sonar.web.https.port=-1
# HTTPS - the alias used to for the server certificate in the keystore.
# If not specified the first key read in the keystore is used.
#sonar.web.https.keyAlias=
# HTTPS - the password used to access the server certificate from the
# specified keystore file. The default value is "changeit".
#sonar.web.https.keyPass=changeit
# HTTPS - the pathname of the keystore file where is stored the server certificate.
# By default, the pathname is the file ".keystore" in the user home.
# If keystoreType doesn't need a file use empty value.
#sonar.web.https.keystoreFile=
# HTTPS - the password used to access the specified keystore file. The default
# value is the value of sonar.web.https.keyPass.
#sonar.web.https.keystorePass=
# HTTPS - the type of keystore file to be used for the server certificate.
# The default value is JKS (Java KeyStore).
#sonar.web.https.keystoreType=JKS
# HTTPS - the name of the keystore provider to be used for the server certificate.
# If not specified, the list of registered providers is traversed in preference order
# and the first provider that supports the keystore type is used (see sonar.web.https.keystoreType).
#sonar.web.https.keystoreProvider=
# HTTPS - the pathname of the truststore file which contains trusted certificate authorities.
# By default, this would be the cacerts file in your JRE.
# If truststoreFile doesn't need a file use empty value.
#sonar.web.https.truststoreFile=
# HTTPS - the password used to access the specified truststore file.
#sonar.web.https.truststorePass=
# HTTPS - the type of truststore file to be used.
# The default value is JKS (Java KeyStore).
#sonar.web.https.truststoreType=JKS
# HTTPS - the name of the truststore provider to be used for the server certificate.
# If not specified, the list of registered providers is traversed in preference order
# and the first provider that supports the truststore type is used (see sonar.web.https.truststoreType).
#sonar.web.https.truststoreProvider=
# HTTPS - whether to enable client certificate authentication.
# The default is false (client certificates disabled).
# Other possible values are 'want' (certificates will be requested, but not required),
# and 'true' (certificates are required).
#sonar.web.https.clientAuth=false
# The maximum number of connections that the server will accept and process at any given time.
# When this number has been reached, the server will not accept any more connections until
# the number of connections falls below this value. The operating system may still accept connections
# based on the sonar.web.connections.acceptCount property. The default value is 50 for each
# enabled connector.
#sonar.web.http.maxThreads=50
#sonar.web.https.maxThreads=50
# The minimum number of threads always kept running. The default value is 5 for each
# enabled connector.
#sonar.web.http.minThreads=5
#sonar.web.https.minThreads=5
# The maximum queue length for incoming connection requests when all possible request processing
# threads are in use. Any requests received when the queue is full will be refused.
# The default value is 25 for each enabled connector.
#sonar.web.http.acceptCount=25
#sonar.web.https.acceptCount=25
# Access logs are generated in the file logs/access.log. This file is rolled over when it's 5Mb.
# An archive of 3 files is kept in the same directory.
# Access logs are enabled by default.
#sonar.web.accessLogs.enable=true
# TCP port for incoming AJP connections. Disabled if value is -1. Disabled by default.
#sonar.ajp.port=-1
#--------------------------------------------------------------------------------------------------
# SEARCH INDEX
# Elasticsearch is used to facilitate fast and accurate information retrieval.
# It is executed in a dedicated Java process.
# JVM options. Note that enabling the HotSpot Server VM mode (-server) is recommended.
#sonar.search.javaOpts=-Xmx256m -Xms256m -Xss256k -Djava.net.preferIPv4Stack=true \
# -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 \
# -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError \
# -Djava.awt.headless=true
# Elasticsearch port. Default is 9001. Use 0 to get a free port.
# This port must be private and must not be exposed to the Internet.
#sonar.search.port=9001
#--------------------------------------------------------------------------------------------------
# UPDATE CENTER
# Update Center requires an internet connection to request http://update.sonarsource.org
# It is enabled by default.
#sonar.updatecenter.activate=true
# HTTP proxy (default none)
#http.proxyHost=
#http.proxyPort=
# NT domain name if NTLM proxy is used
#http.auth.ntlm.domain=
# SOCKS proxy (default none)
#socksProxyHost=
#socksProxyPort=
# proxy authentication. The 2 following properties are used for HTTP and SOCKS proxies.
#http.proxyUser=
#http.proxyPassword=
#--------------------------------------------------------------------------------------------------
# LOGGING
# Level of information displayed in the logs: NONE (default), BASIC (functional information)
# and FULL (functional and technical details)
#sonar.log.profilingLevel=NONE
# Path to log files. Can be absolute or relative to installation directory.
# Default is /logs
#sonar.path.logs=logs
#--------------------------------------------------------------------------------------------------
# OTHERS
# Delay in seconds between processing of notification queue. Default is 60 seconds.
#sonar.notifications.delay=60
# Paths to persistent data files (embedded database and search index) and temporary files.
# Can be absolute or relative to installation directory.
# Defaults are respectively /data and /temp
#sonar.path.data=data
#sonar.path.temp=temp
#--------------------------------------------------------------------------------------------------
# DEVELOPMENT - only for developers
# Dev mode allows to reload web sources on changes and to restart server when new versions
# of plugins are deployed.
#sonar.web.dev=false
# Path to webapp sources for hot-reloading of Ruby on Rails, JS and CSS (only core,
# plugins not supported).
#sonar.web.dev.sources=/path/to/server/sonar-web/src/main/webapp
4.6.5. ansible
Este rol se encarga de instalar ansible, exactamente de la misma manera en la que antes lo instalamos en nuestra máquina. La razón por la que necesitamos ansible en remoto es para automatizar tareas como los despliegues de la aplicación
roles/ansible/tasks/main.yml
---
# file: roles/ansible/tasks/main.yml
- name: install python setup tools
apt: name=python-setuptools state=present update_cache=yes
tags: ansible
- name: install pip to manage ansible installation
command: easy_install pip
tags: ansible
- name: install ansible with pip
command: pip install ansible
tags: ansible
4.6.6. jenkins
Este rol se encarga de instalar jenkins y sus plugins
roles/jenkins/tasks/main.yml
---
# file: /roles/jenkins/tasks/main.yml
- name: add apt key for jenkins
apt_key: url="{{jenkins.apt_key}}" state=present
tags: jenkins
- name: add apt repository for jenkins
apt_repository: repo="{{jenkins.repo}}" state=present
tags: jenkins
- name: install jenkins
apt: name=jenkins update_cache=yes
tags: jenkins
- name: create plugins directory
file: path="{{jenkins.base_dir}}/plugins" state=directory owner=jenkins group=jenkins
tags: jenkins
- name: copy jenkins properties
copy: src={{item}} dest="/etc/default/jenkins"
with_items:
- jenkins
tags: jenkins
- name: ensure plugins are present
get_url: url="{{jenkins.plugins_url}}/{{item}}.hpi" dest="{{jenkins.base_dir}}/plugins/{{item}}.jpi" owner=jenkins group=jenkins
with_items:
- sonar
- github-oauth
- credentials
- git-client
- scm-api
- git
- github-api
- github
notify: restart jenkins
tags: jenkins
Lo más destacable es la propiedad notify en la última tarea. La acción restart jenkins es denominada por ansible como handlers, y son acciones que se escriben a parte porque pueden ser reutilizadas por varias tareas del mismo rol.
Por lo tanto para que nuestro rol funcione necesitamos el handler del rol jenkins:
roles/jenkins/handlers/main.yml
---
# file: /roles/jenkins/handlers/main.yml
- name: restart jenkins
service: name=jenkins state=restarted
Como se puede observar, el nombre del handler debe ser igual a la propiedad -name de ansible.
En la tarea:
- name: copy jenkins properties
copy: src={{item}} dest="/etc/default/jenkins"
with_items:
- jenkins
tags: jenkins
En la propiedad src no estamos indicandole la ruta. cuando esto sucede, ansible busca por defecto en el directorio files dentro de la carpeta de su rol. Este fichero sobreescribe las propiedades por defecto de jenkins para cambiar el context path de / a /jenkins:
roles/jenkins/files/jenkins
# defaults for jenkins continuous integration server
# pulled in from the init script; makes things easier.
NAME=jenkins
# location of java
JAVA=/usr/bin/java
# arguments to pass to java
JAVA_ARGS="-Djava.awt.headless=true" # Allow graphs etc. to work even when an X server is present
#JAVA_ARGS="-Xmx256m"
#JAVA_ARGS="-Djava.net.preferIPv4Stack=true" # make jenkins listen on IPv4 address
PIDFILE=/var/run/$NAME/$NAME.pid
# user and group to be invoked as (default to jenkins)
JENKINS_USER=$NAME
JENKINS_GROUP=$NAME
# location of the jenkins war file
JENKINS_WAR=/usr/share/$NAME/$NAME.war
# jenkins home location
JENKINS_HOME=/var/lib/$NAME
# set this to false if you don't want Hudson to run by itself
# in this set up, you are expected to provide a servlet container
# to host jenkins.
RUN_STANDALONE=true
# log location. this may be a syslog facility.priority
JENKINS_LOG=/var/log/$NAME/$NAME.log
#JENKINS_LOG=daemon.info
# OS LIMITS SETUP
# comment this out to observe /etc/security/limits.conf
# this is on by default because http://github.com/jenkinsci/jenkins/commit/2fb288474e980d0e7ff9c4a3b768874835a3e92e
# reported that Ubuntu's PAM configuration doesn't include pam_limits.so, and as a result the # of file
# descriptors are forced to 1024 regardless of /etc/security/limits.conf
MAXOPENFILES=8192
# set the umask to control permission bits of files that Jenkins creates.
# 027 makes files read-only for group and inaccessible for others, which some security sensitive users
# might consider benefitial, especially if Jenkins runs in a box that's used for multiple purposes.
# Beware that 027 permission would interfere with sudo scripts that run on the master (JENKINS-25065.)
#
# Note also that the particularly sensitive part of $JENKINS_HOME (such as credentials) are always
# written without 'others' access. So the umask values only affect job configuration, build records,
# that sort of things.
#
# If commented out, the value from the OS is inherited, which is normally 022 (as of Ubuntu 12.04,
# by default umask comes from pam_umask(8) and /etc/login.defs
# UMASK=027
# port for HTTP connector (default 8080; disable with -1)
HTTP_PORT=8080
# port for AJP connector (disabled by default)
AJP_PORT=-1
# servlet context, important if you want to use apache proxying
PREFIX=/$NAME
# arguments to pass to jenkins.
# --javahome=$JAVA_HOME
# --httpPort=$HTTP_PORT (default 8080; disable with -1)
# --httpsPort=$HTTP_PORT
# --ajp13Port=$AJP_PORT
# --argumentsRealm.passwd.$ADMIN_USER=[password]
# --argumentsRealm.roles.$ADMIN_USER=admin
# --webroot=~/.jenkins/war
# --prefix=$PREFIX
JENKINS_ARGS="--webroot=/var/cache/$NAME/war --httpPort=$HTTP_PORT --ajp13Port=$AJP_PORT --prefix=/jenkins"
4.6.7. maven
Este rol se encarga de instalar maven.
roles/maven/tasks/main.yml
---
#file: /roles/maven/tasks/main.yml
- name: download maven 3.3.3
get_url: url="{{maven.download_url}}" dest="/tmp/{{maven.file}}"
tags: maven
- name: extract maven
unarchive: src="/tmp/{{maven.file}}" dest=/opt copy=no
tags: maven
- name: create link to maven folder
file: src="{{maven.home}}" dest=/opt/maven state=link
tags: maven
- name: tell the machine to use our maven
alternatives: name=mvn link=/usr/bin/mvn path=/opt/maven/bin/mvn
tags: maven
- name: create .m2 folder
file: path="{{jenkins.base_dir}}/.m2" state=directory owner=jenkins group=jenkins
tags: maven
El único módulo a destacar es alternatives, usado cuando hay multiples programas instalados que proveen funcionalidad similar.
4.6.8. nexus
Este rol se encarga de instalar nexus, nuestro repositorio de artefactos binario.
roles/nexus/tasks/main.yml
---
# file: /roles/nexus/tasks/main.yml
- name: create nexus group
group: name=nexus state=present
tags: nexus
- name: create nexus user
user: name=nexus comment="Nexus" group=nexus createhome=yes
tags: nexus
- name: download nexus
get_url: url="{{nexus.download_url}}" dest=/tmp/nexus
tags: nexus
- name: extract nexus
unarchive: src=/tmp/nexus dest="{{nexus.base_dir}}" copy=no
tags: nexus
- name: update the symbolic link to nexus install
file: path="{{nexus.home}}" src="{{nexus.base_dir}}/nexus-{{nexus.version}}" owner=nexus group=nexus state=link force=yes
tags: nexus
- name: set NEXUS_HOME environment variable
lineinfile: dest=/etc/environment regexp="^export NEXUS_HOME.*" line="export NEXUS_HOME={{nexus.home}}" insertbefore="^PATH.*"
tags: nexus
- name: move work directory to data directory
shell: mv {{nexus.base_dir}}/sonatype-work {{nexus.data_dir}}/sonatype-work
tags: nexus
- name: change nexus work directory in nexus.properties file
replace: dest="{{nexus.home}}/conf/nexus.properties" regexp="^nexus-work=(.*)$" replace="nexus-work={{nexus.data_dir}}/sonatype-work"
tags: nexus
- name: change ownership of nexus home
file: path="{{nexus.base_dir}}/nexus-{{nexus.version}}" owner=nexus group=nexus recurse=yes
tags: nexus
- name: change ownership of nexus data directory
file: path="{{nexus.data_dir}}" owner=nexus group=nexus recurse=yes
tags: nexus
- name: make nexus runned by nexus user
replace: dest="{{nexus.home}}/bin/nexus" regexp="#RUN_AS_USER=(.*)$" replace="RUN_AS_USER=nexus"
tags: nexus
- name: change nexus home in binary file
replace: dest="{{nexus.home}}/bin/nexus" regexp="^NEXUS_HOME=(.*)" replace="NEXUS_HOME={{nexus.home}}"
tags: nexus
- name: change nexus piddir in binary file
replace: dest="{{nexus.home}}/bin/nexus" regexp="^#PIDDIR=(.*)" replace="PIDDIR=/home/nexus"
tags: nexus
- name: create symbolic link to /etc/init.d/nexus
file: src="{{nexus.home}}/bin/nexus" dest=/etc/init.d/nexus state=link
tags: nexus
- name: make nexus script executable
file: path="{{nexus.home}}/bin/nexus" mode=0755
tags: nexus
- name: enable nexus service
service: name=nexus enabled=yes
notify: restart nexus
tags: nexus
Nexus también posee un handler que restaura el servicio, por lo que lo creamos:
roles/nexus/handlers/main.yml
---
# file: /roles/nexus/handlers/main.yml
- name: restart nexus
service: name=nexus state=restarted
4.6.9 apache
Este rol se encarga de la instalación y la confi
roles/apache/tasks/main.yml
---
#file: /roles/apache/tasks/main.yml
- name: install apache2
apt: name=apache2 state=latest update_cache=yes
tags: apache
- name: install apache2-utils for authentication
apt: name=apache2-utils state=latest update_cache=yes
tags: apache
- name: enable mod_proxy module
apache2_module: name={{item}} state=present
with_items:
- proxy
- proxy_http
- rewrite
- headers
- ssl
notify: restart apache
tags: apache
- name: create certificate folder
file: path="{{apache.ssl_folder}}" state=directory
tags: apache
- name: copy SSL certificate
copy: src={{item}} dest="{{apache.ssl_folder}}"
with_items:
- dev.example.crt
- dev.example.key
tags: apache
- name: copy virtualhost conf
template: src=virtualhost.conf dest="/etc/apache2/sites-available/{{apache.server_name}}.conf"
tags: apache
- name: enable virtualhost conf
command: a2ensite {{apache.server_name}}
notify: restart apache
tags: apache
- name: remove default virtualhost file
file: path=/etc/apache2/sites-enabled/000-default.conf state=absent
notify: restart apache
tags: apache
En la tarea copy ssl certificate actualmente se enviarían los dos archivos necesarios para que apache funcionara con ssl, de modo que introduciendo en la carpeta files/ tus certificados ansible se encargaría de realizar el resto de la configuración.
Este rol también necesita de un handler para reiniciar el servicio de apache:
roles/apache/handlers/main.yml
---
#file: /roles/apache/handlers/main.yml
- name: restart apache
service: name=apache2 state=restarted
Por último, le pasamos la configuración del virtual host de forma que apache actúe como un reverse proxy a la hora de acceder a los servicios de sonar, jenkins y nexus.
NOTA: la configuración para que este acceso a servicios sea via https está DESHABILITADA. Se recomienda crear par de claves para la autenticación ssl. Después solo es necesario descomentar la parte comentada en el primer virtual host y eliminar las propiedades del proxy del mismo.
roles/apache/templates/virtualhost.conf
#ServerName {{apache.server_name}}
#Redirect all http traffic to https if it is pointed at /jenkins /nexus /sonar
#RewriteEngine On
#RewriteCond %{HTTPS} off
#RewriteCond %{REQUEST_URI} ^/(jenkins|nexus|sonar)/?.*$
#RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
Order deny,allow
Allow from all
ProxyRequests Off
ProxyPass /sonar {{apache.sonar_http}}
ProxyPassReverse /sonar {{apache.sonar_http}}
ProxyPass /nexus {{apache.nexus_http}}
ProxyPassReverse /nexus {{apache.nexus_http}}
ProxyPass /jenkins {{apache.jenkins_http}} nocanon
ProxyPassReverse /jenkins {{apache.jenkins_http}}
AllowEncodedSlashes NoDecode
CustomLog /var/log/apache2/{{apache.custom_log_file}} combined
ErrorLog /var/log/apache2/{{apache.error_log_file}}
SSLEngine on
SSLCertificateFile {{apache.certificate_file}}
SSLCertificateKeyFile {{apache.certificate_key_file}}
SetEnvIf User-Agent ".*MSIE.*" nokeepalive ssl-unclean-shutdown
Order deny,allow
Allow from all
ProxyRequests Off
ProxyPass /sonar {{apache.sonar_http}}
ProxyPassReverse /sonar {{apache.sonar_http}}
ProxyPass /nexus {{apache.nexus_http}}
ProxyPassReverse /nexus {{apache.nexus_http}}
ProxyPass /jenkins {{apache.jenkins_http}} nocanon
ProxyPassReverse /jenkins {{apache.jenkins_http}}
AllowEncodedSlashes NoDecode
CustomLog /var/log/apache2/{{apache.custom_https_log}} combined
ErrorLog /var/log/apache2/{{apache.error_https_log}}
5. Arranque de la máquina virtual
Una vez creados los roles del playbook, simplemente levantamos la máquina virtual con el comando:
vagrant up
Esto levantará la máquina virtual y llamará a ansible para que instale y configure todos los elementos del entorno que hemos visto previamente en los roles. Hay que tener en cuenta que ansible lo único que hace es ejecutar todos los comando que haríamos nosotros de forma automática, así que la primera vez que ejecutemos el comando tardará sus 10-15 minutos ![😀]()
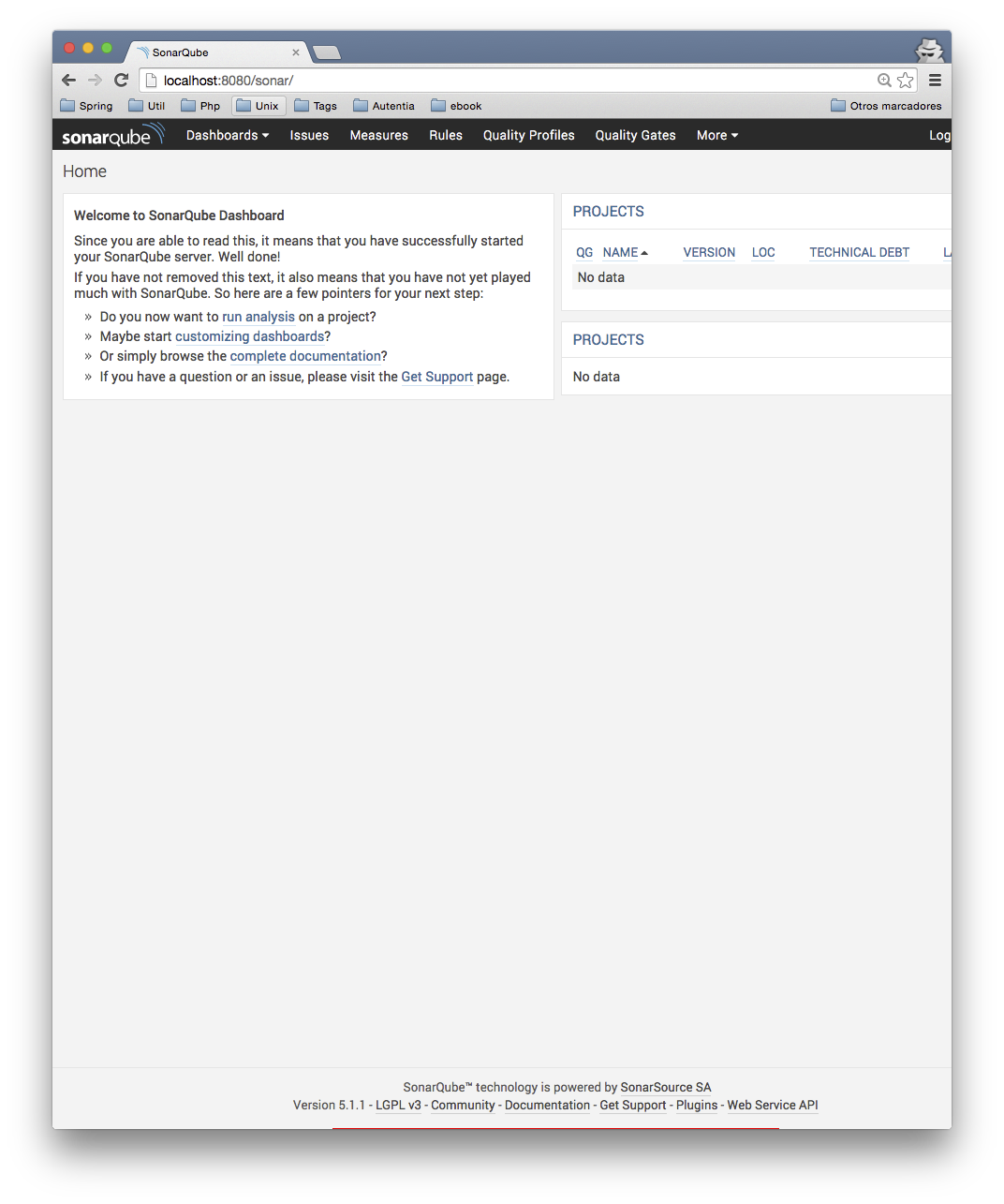
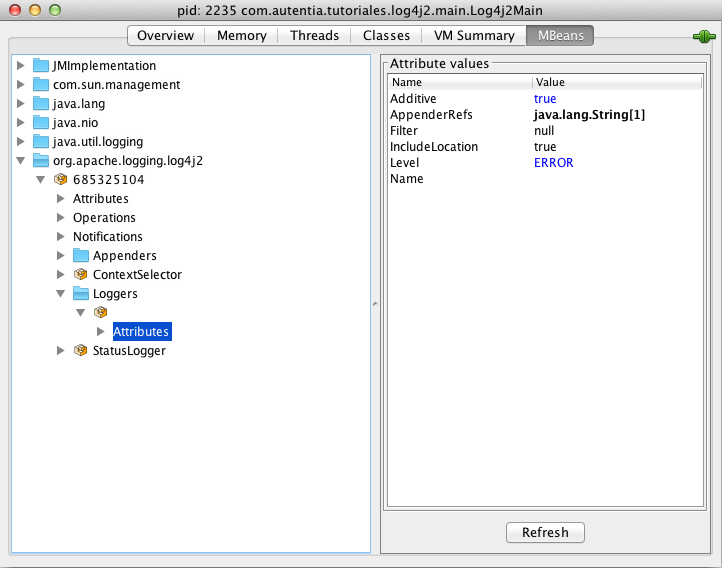
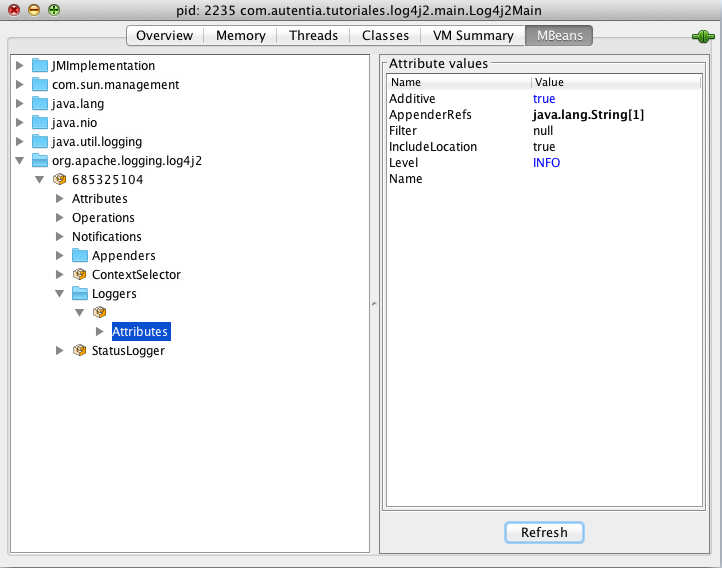
6. Comprobación del funcionamiento
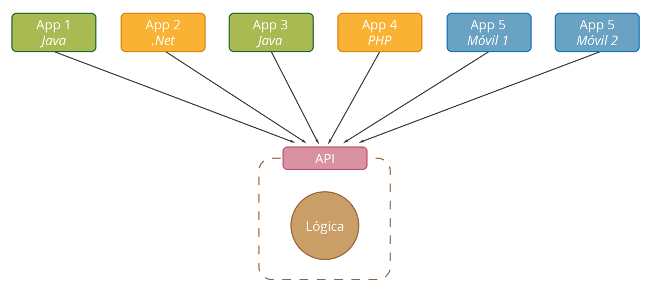
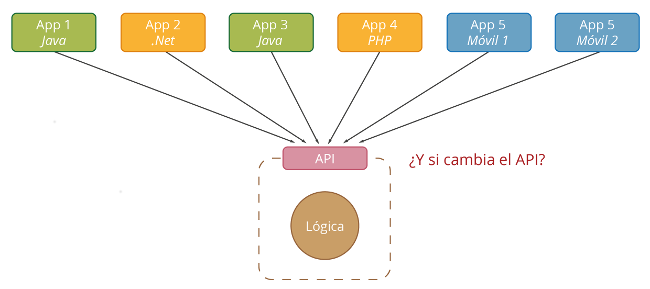
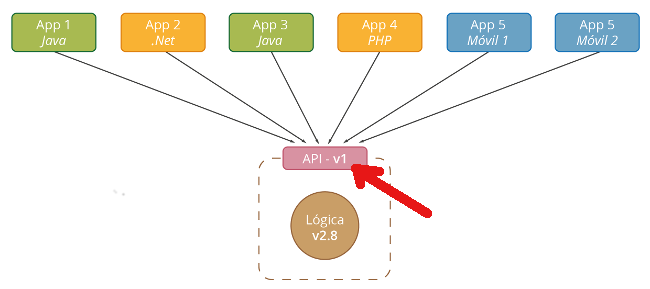
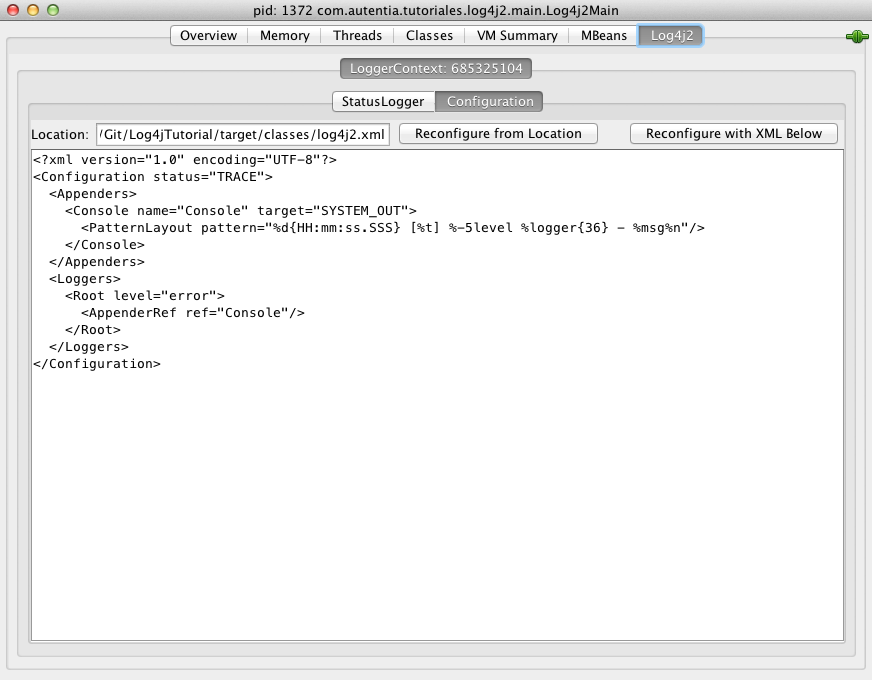
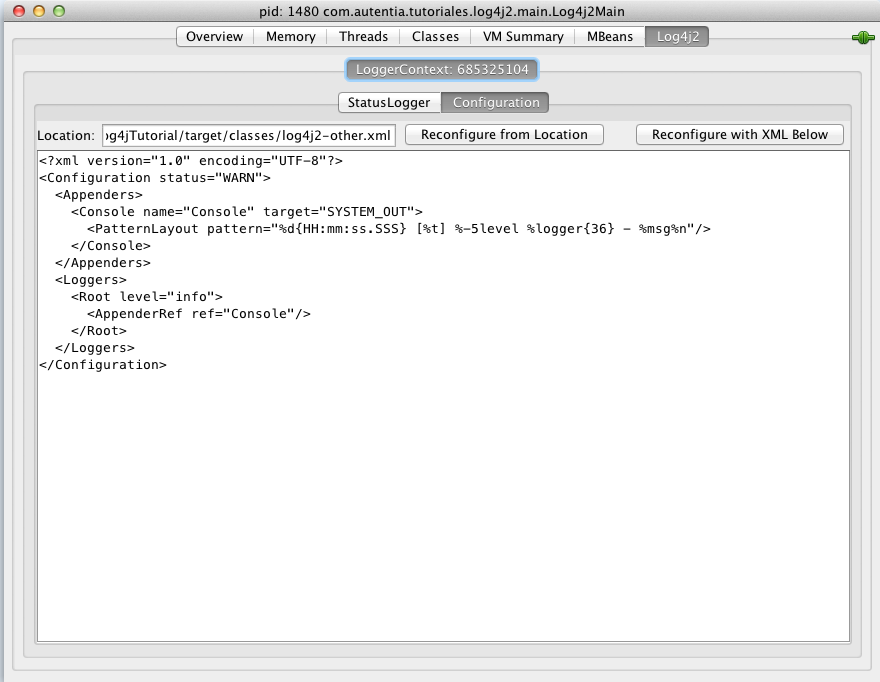
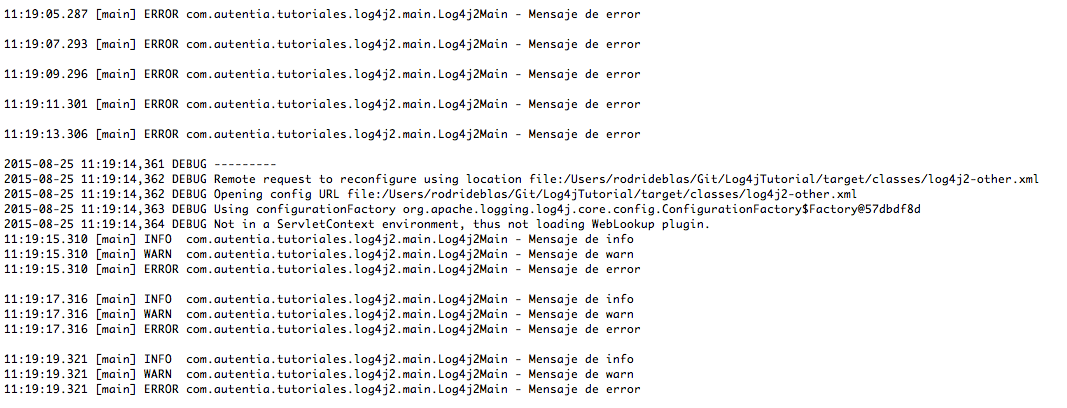
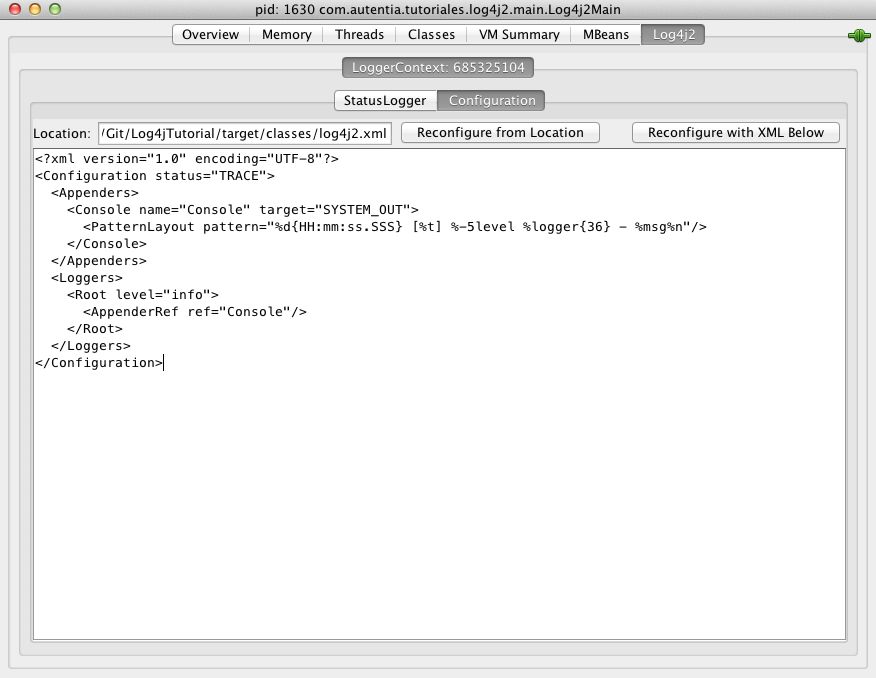
Para comprobar su funcionamiento con nuestro navegador vamos a http://localhost:8080/jenkins y comprobamos como nos hace una redirección al servicio de jenkins. El motivo de usar el puerto 8080 es que en el fichero de configuración de la máquina virtual creamos una redirección del puerto 8080 en el host al puerto 80 de la máquina virtual para poder comprobar nuestros cambios. En caso de que usemos ansible para configurar una máquina externa, no sería necesario definir esta propiedad, sino que nos refeririamos directamente al puerto 80 de esa máquina.
Si nos fijamos en la url escrita, se ve como ocultamos los puertos internos de la aplicación, usando solo el puerto 80 del apache, que está redirigido al puerto 8080 de la máquina real.
![img2]()
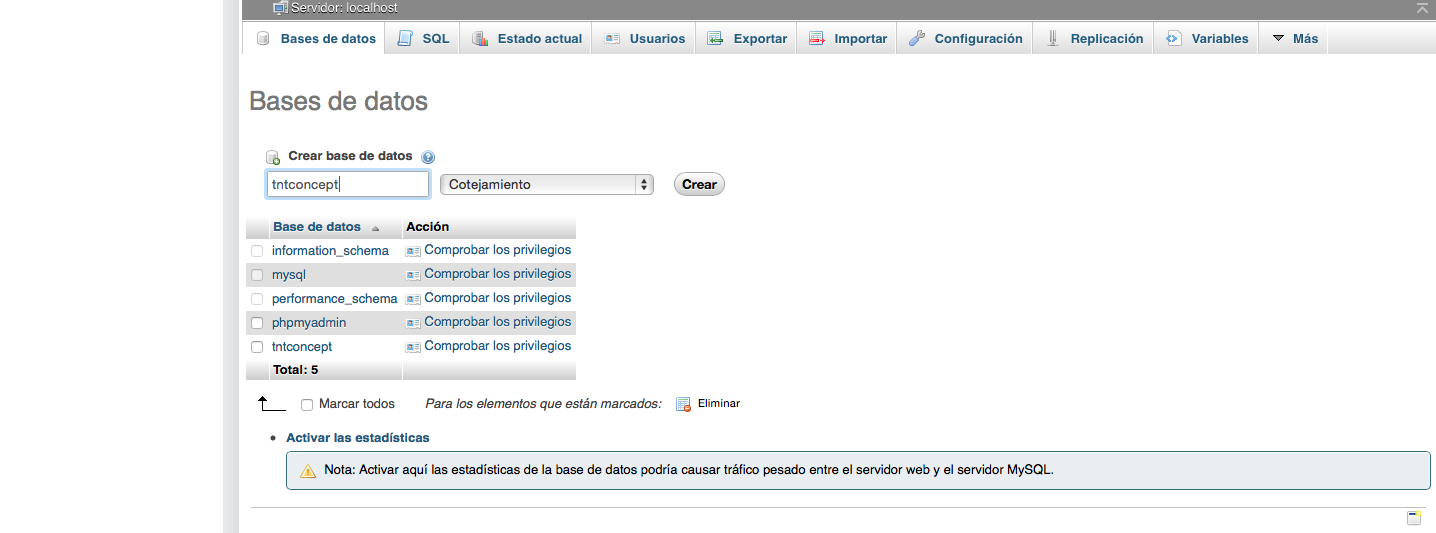
![img3]()
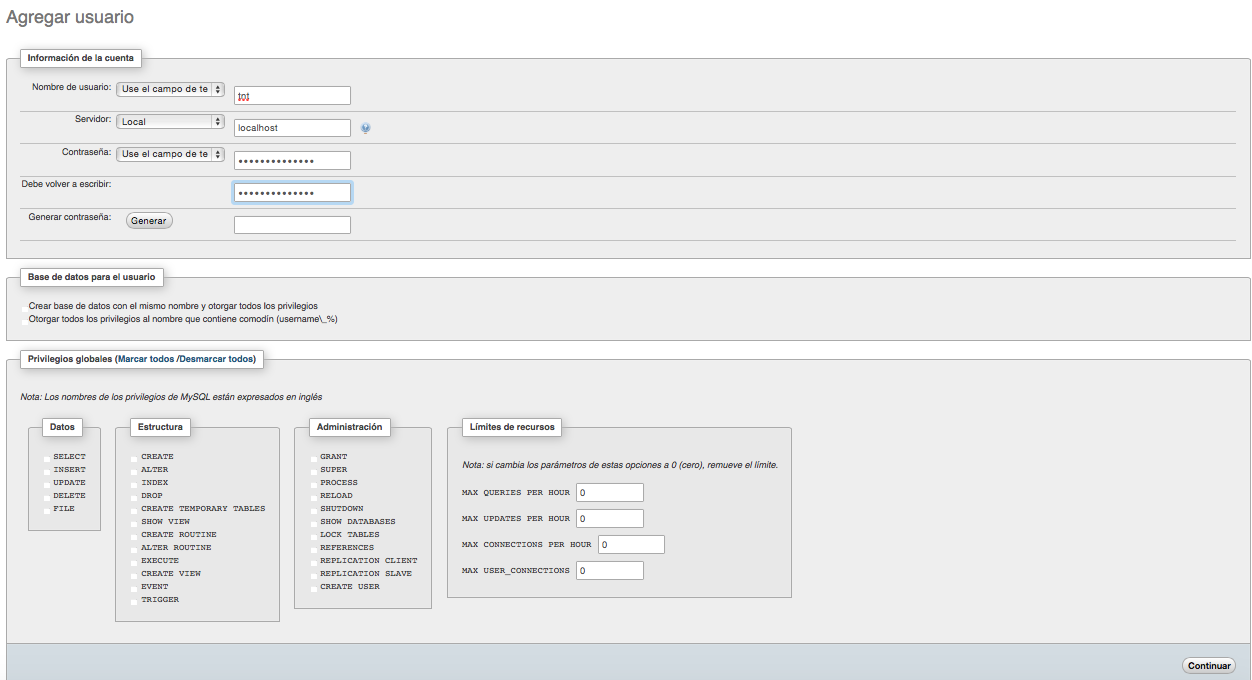
![img4]()
Puedes descargar la configuración de vagrant y ansible de este tutorial desde aquí
7. Conclusiones
Gracias a la combinación de vagrant y ansible, somos capaces de crear un entornos con gran facilidad, de modo que no solo sirva para crear entornos de integración, si no también entornos para el equipo de desarrollo.
8. Referencias