En este tutorial vamos a ver una breve introducción a Express, un framework MVC de NodeJS para hacer páginas Web y servicios REST.
0. Índice de Contenidos
1. Introducción
Al comienzo, usar JavaScript en el lado del servidor parecía una excentricidad: un proyecto loco que quería retorcer la tecnología para escribir una aplicación completa, tanto en cliente como en servidor con este lenguaje. Muchos pensábamos que no tenía ninguna viabilidad en el mundo real, pero nos equivocamos de pleno. Con el paso de los años se ha demostrado lo útil e interesante que está siendo la plataforma NodeJS, tanto para la ejecución de scripts en el ordenador como para servir de base para los nuevos servidores.
Y es que Javascript es un lenguaje con unas características que se adaptan bastante bien a las necesidades actuales, sobre todo en cuanto a asincronía, programación funcional y orientada a objetos, lenguaje dinámico y rapidez en el desarrollo, gracias a un prácticamente maduro ecosistema de aplicaciones y herramientas de soporte.
Dentro de las posibilidades que nos brinda NodeJS está la de crear un servidor Web con Javascript. De hecho, dentro de los módulos de NodeJS lleva uno básico incorporado como veremos. Pero si queremos hacer una aplicaicón minimamente organizada, necesitaremos un framework en el que basarnos para no volver a reinventar la rueda.
Como ya sabrás, si hablamos de frameworks para aplicaciones Web, tenemos que hablar del famoso patrón MVC (Modelo-Vista-Controlador), que se ha mostrado hasta ahora como la organización ideal: Struts, Spring MVC, ASP .NET, Code Igniter o Laravel en PHP… Así que NodeJS no podía ser menos y cuenta también con los suyos, donde el más reconocido es Express.
Vamos a ver cómo instalar Express en nuestra máquina Ubuntu (más o menos es lo mismo para otros sistemas operativos) y cómo dar los primero pasos con este framework, entendiendo su estructura y funcionamiento.
2. Instalación
Partimos de un Ubuntu 16.04 recién instalado, asi que hay que cargar algunos programas si no los tienes instalados…
Comenzaremos por el propio NodeJS
sudo apt-get install nodejs -y
Ahora instalamos el gestor de paquetes NPM (Node Package Manager), que nos permitirá instalar aplicaciones basadas en NodeJS
sudo apt-get install npm
Creamos un directorio par albergar nuestra aplicación
mkdir expressAdictos
Lo mejor para comenzar a utilizar Express ya mismo es que empleemos un generador que nos va a crear toda la estructura de directorios básica, con ficheros de demostración. Así, además podremos ver la estructura básica de una aplicación Express y nos ahorraremos un buen trabajo.
Ejecutamos en un terminal para instalar el generador de la versión 4.X:
* Quizá le tengas que dar permisos de administrador porque tiene que acceder a “/usr/local/lib”.
npm install -g express-generator@4
Con el parámetro -g indicamos que sea un comando disponible para todo el sistema en el que lo instalamos.
Ahora vamos a decirle al generador que genere la estructura en el directorio expressAdictos que hemos creado.
express expressAdictos/
Así creará una serie de directorios y ficheros básicos para comenzar a trabajar con Express
![1]()
Pero aún no hemos acabado: accedemos al directorio porque vamos a modificar el fichero package.json. Si vienes del mundo de Java, este fichero es como el fichero pom.xml de Maven: indica dependencias y algunas propiedades del proyecto, como versiones, nombres, comandos…
Vamos dentro del directorio y ejecutamos:
npm init
Mediante unas preguntas podremos configurar versión, repo de Git, licencia, autor… Esta información se une a la ya creada por el generador de express, como son las dependencias o indicación del script de inicio del servidor:
![2]()
Ahora vamos a instalar un par de utilidades básicas e imprescindibles para desarrollar. Sí, estoy hablando de las herramientas para hacer testing. A mí me gusta Mocha y Chai como base, aunque se pueden añadir otras como Jasmine por ejemplo.
Las podemos instalar muy fácilmente gracias a NPM:
npm install chai --save-dev
npm install mocha --save-dev
Con el parámetro –save-dev logramos que, además de instalarlas, queden las dependencias reflejadas en las dependencias de desarrollo. Tambien podríamos haber puesto “-D” que es más corto :). Aquí podemos ver estas dependencias…
"devDependencies": {
"chai": "^3.5.0",
"mocha": "^2.4.5"
}
Y ya que estamos, podemos añadir el comando para hacer test al package.json, justo al lado del comando start en el apartado de scripts. Es decir, quedaría algo así:
"scripts": {
"start": "node ./bin/www",
"test": "mocha"
},
Con esto, podemos crear un directorio /test donde dejaremos los archivos de test de la aplicación:
mkdir test
Así, cuando escribamos npm test, se ejecutará el comando “mocha”, que buscará los test en el directorio “test” (su comportamiento por defecto).
También, podemos instalar mocha como un comando del sistema (como sucede con express) para que pueda ser invocado desde cualquier lugar de nuestro ordenador. Es muy fácil, otra vez podemos instalar con la opción “-g”
* Puede que necesites emplear de nuevo “sudo” porque tiene que escribir en el directorio “/usr/local/bin”.
sudo npm install mocha -g
3. Arrancando el servidor
Ya deberíamos tener todo lo necesario para acceder a la aplicacion básica que se ha generado con el generador de Express que hemos utilizado. Vamos a iniciar el servidor.
Quizá te estés preguntando dónde está el servidor… no hemos hablado de nada de Apache, ni IIS, ni Tomcat… ¿No es extraño?
Realmente no es tan extraño: lo lleva la propia aplicación incorporada gracias a las librerías que utiliza NodeJS. Simplemente dentro del código de la aplicación se invoca a una librería con el servidor, se configura y se arranca.
Para iniciarlo, tenemos que ejecutar el comando de npm para arrancar un proyecto de NodeJS:
npm start
¿Qué hace esto? Realmente va al package.json y comprueba el comando que está configurado como “start”, que no es otro que:
"start": "node ./bin/www"
Si vamos al directorio “bin” de la aplicación, podremos ver el fichero “www” que es el que se ejecuta. Luego analizaremos en detalle su contenido. Ahora nos quedaremos con las consecuencias, que no son otras que nuestra primera aplicacion en Express funcionando.
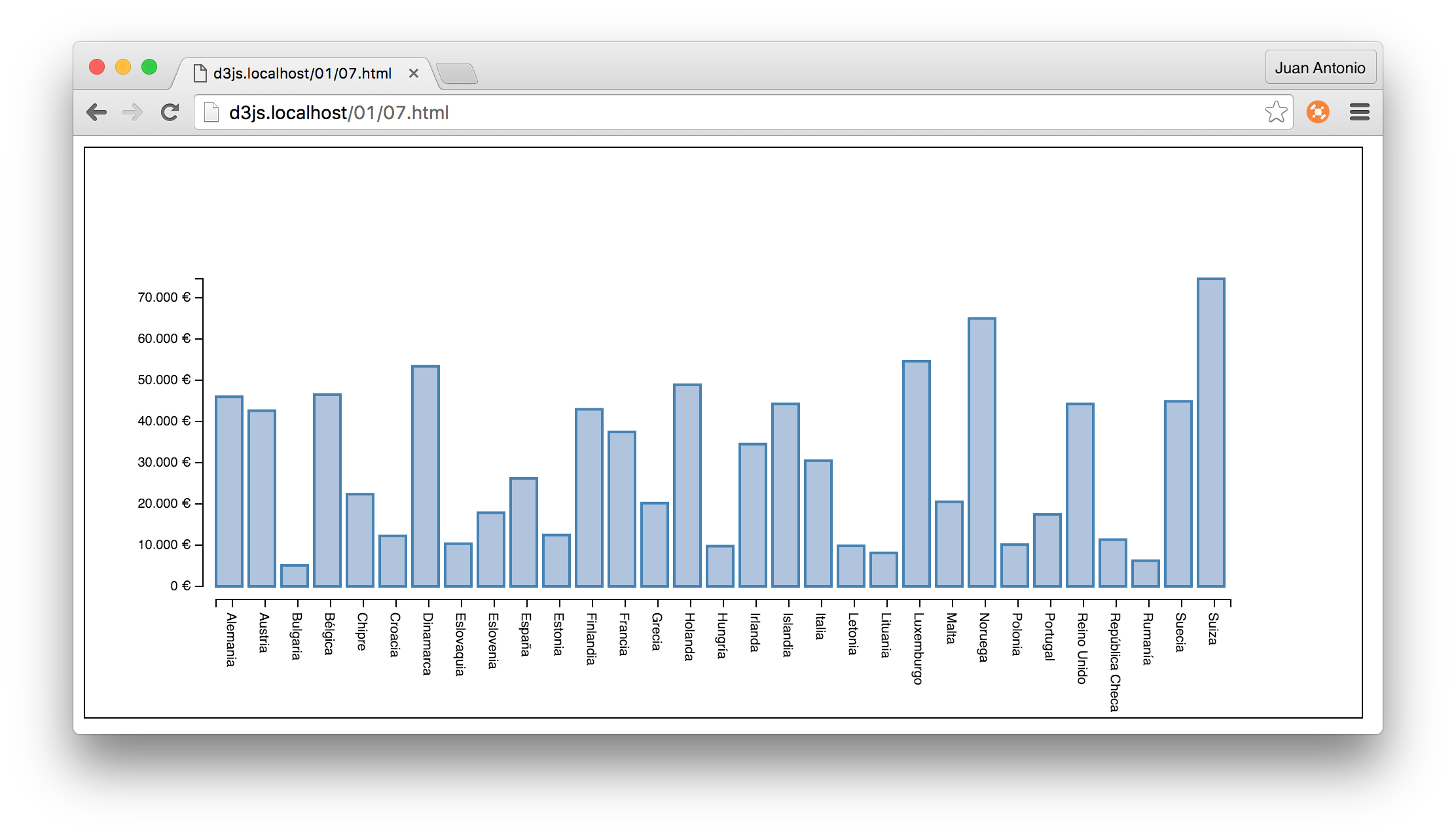
Esto es lo que se ve en el navegador si ponemos http://localhost:3000
![4]()
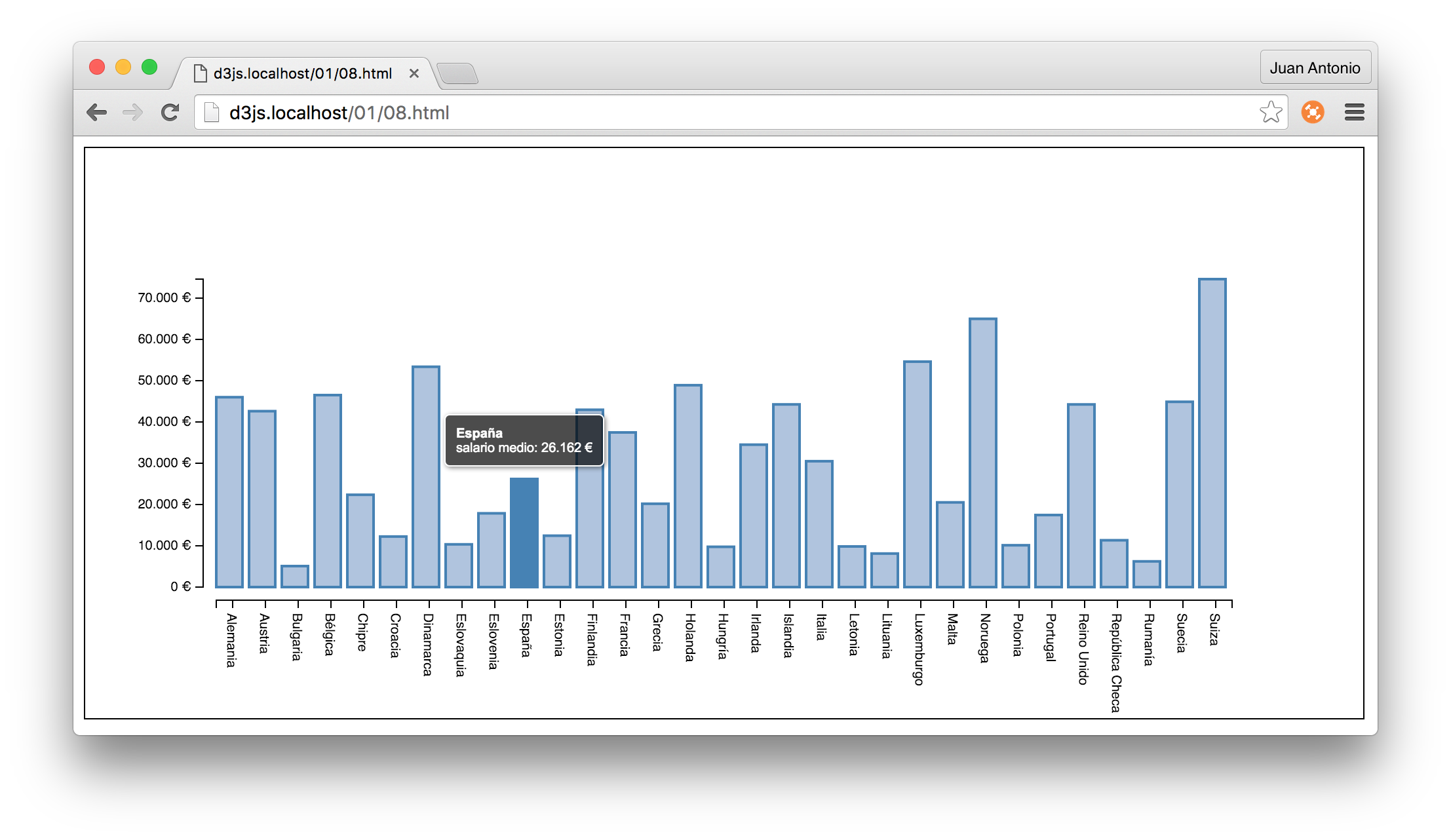
Y esto es lo que se ve en la salida de la consola:
![3]()
Por defecto, emplea la consola desde la que estamos ejecutando como salida, así que si pulsamos CTRL+C para cancelar la ejecución o cerramos la ventana, el servidor se cortará.
¡Ah!, quizá si no te funciona por versiones de librerías tengas que hacer un npm update
npm update
4. Extructura de una aplicación Express
Vamos a ver una pequeña introdución a la estructura de la aplicación para que sepas dónde tienes que meter tu código y entiendas lo básico sobre su funcionamiento.
4.1. El Servidor
Como he indicado antes, el arranque se lleva a cabo en el fichero /bin/www. Sí es un nombre raro “www” pero es el que le han dado. Si hacemos un “cat” sobre el fichero nos llamarán la atención algunas líneas (omito con puntos suspensivos “…” otras instrucciones):
...
var app = require('../app');
var http = require('http');
...
var port = normalizePort(process.env.PORT || '3000');
...
app.set('port', port);
...
var server = http.createServer(app);
Básicamente se encarga de:
- Cargar los módulos app.js y http. El primero es del propio express y contiene lo necesario para configurar la aplicación y cargar el resto de módulos de express. El módulo http por su parte es el propio servidor
- Establece una variable “port” a valor 3000 si no se ha indicado otro por entorno. Si cambiamos este 3000 por cualquier otro puerto, es válido (siempre que no esté ocupado, claro).
- Establece el valor del puerto como una propiedad de la aplicación.
- Y arranca el servidor http creando el servidor para la aplicación establecida en app.js.
Y ya está… con esto tenemos el servidor funccionando. Lo he congelado con un tag en mi repositorio de Git por si quieres ver cómo estaba en este momento:
https://github.com/4lberto/expressAdictos/releases/tag/Start
4.2. El Modelo-Vista-Controlador
Como la mayoría de frameworks para el mundo web, se basa en el patrón Modelo-Vista-Controlador (MVC). Esto nos facilita mucho las cosas si estamos acostumbrados a este patrón: Spring MVC, Struts, AngularJS…:
- Modelo: las clases de datos que se manejan en la aplicación.
- Vista: la representación para el usuario. Por ejemplo páginas Web (HTML) o JSON en REST.
- Controlador: donde se realiza el procesamiento del modelo para dárselo “masticado” a la vista. Contiene la lógica de negocio.
Vamos a ver parte por parte dónde se ubican, aunque mejor en el orden natural de una petición: controlador, modelo y vista.
4.3. Controlador (middleware)
La parte de controlador tiene mucho que ver con el enrutamiento y con lo que en Express llaman middleware: funciones que reciben una entrada (request) y una salida (response). Lo que sucede entre la entrada y la salida es el controlador.
Para que se seleccione una u otra función de middleware hace falta mapear las funciones a una url determinada. Aquí tenemos dos opciones:
- Mapear al objeto aplicación con app.use(“url”, funciónMiddleware), o con app.[MétodoHTTP] como por ejemplo app.get o app.post;
- Mapear a un objeto router. Se hace del mismo modo: router.use(“url”, funcionMiddleware) o también con route.[MétodoHTTP] como por ejemplo route.delete o route.post.
La diferencia entre uno y otro método es más bien de organización. Si nos decantamos por app.use (o sus derivados) se mapeará a la aplicación directamente. Si usamos un router, lo hará al router, pero con la ventaja de que este es más específico y podremos, por ejemplo, aplicarle funciones de autentiación.
Si ahora te digo que lo adecuado es mapear un router a un objecto aplicación, igual lo ves más claro:
var myRouter = express.Route();
app.use("/coches", myRouter);
myRouter.use(/carreras, function(.....));
¿Y qué contienen las funciones de middleware? Muy fácil. Vamos a routes/indes.js para ver el ejemplo que viene con el generador
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
module.exports = router;
Como puedes intuir, se mapea en la url “/” (raíz) de este router que está en el fichero index.js (sí, se ha separado en un fichero nuevo). Dentro, lo que hace es reenviar con res.render la salida al fichero de vista index.jade, pasándole el modelo para que lo pinte, que es un JSON con atributo “title” con vaor “Express”
¿Dónde se incluye este router index.js? Pues en el fichero app.js de la aplicación principal. Como te he adelantado antes, lo que hace es registrar el router en la aplicación:
...
var routes = require('./routes/index');
...
app.use('/', routes);
Muy fácil: 2 pasos nada más. Con el primero se carga el fichero index.js y se asigna a la variable “routes”. En el segundo paso, asigna a la URl “/” ese router. Entonces cuando accedamos a http://localhost:3000/, nos redirigirá al index.jade con el atributo “title” con valor “Express”. Fácil y sencillo.
Como dice la documentación oficial http://Express.com/es/guide/using-middleware.html, se pueden soportar varios middleware para un solo mapeo de URL. Una vez pasado por uno, se llama al siguiente con “next()”. Un ejemplo que se incluye en la documentación:
app.use('/user/:id', function(req, res, next) {
console.log('Request URL:', req.originalUrl);
next();
}, function (req, res, next) {
console.log('Request Type:', req.method);
next();
});
Pasa por la primera función de middleware y le pasa la ejecución a la siguiente.
¿Y qué más puedo hacer con las funciones de middlware?
Además de pasar al siguiente con “next()” y reenviar a una vista con “res.send()” como hemos visto antes, puedes enviar al siguiente router que cuadre en la url con “next(‘route’)” (tal cual) o puedes escribir directamente en la respuesta con res.send(‘Mensaje’);
Esto es lo que muestra el ejemplo que viene en el fichero users.js, que está mapeado a la url (‘/users’) en el fichero app.js. Su contenido es:
router.get('/', function(req, res, next) {
res.send('respond with a resource');
});
Si lo pruebas verás que pone ‘respond with a resource’.
Igual que hemos puesto un texto, podremos devolver un JSON fácilmente, simplemente pasando por parámetro un objeto de Javascript (que para eso es JSON). Asi que hacer un API REST con express es muy sencillo.
Por ejemplo, si tengo un nuevo router que response a “/rest” con este contenido en la función de middleware:
router.get('/', function(req, res, next) {
var persona={nombre:'4lberto'};
res.send(persona);
});
La salida, será la representación del objeto persona en JSON, sin hacer nada más (pobre Jackson de Java, no tiene nada que hacer aquí =()
{"nombre":"4lberto"}
¿Y si quiero añadir un controlador nuevo?
Existen varias formas como hemos visto, pero la forma de organizar que nos propone esta plantilla de Express creo que está bien.
Creamos el fichero coches.js en /routes con este contenido:
var express = require('express');
var router = express.Router();
/* GET users listing. */
router.get('/carreras', function(req, res, next) {
res.send('Response con un coche de carreras');
});
router.get('/:id', function(req, res, next) {
res.send('Responde con el coche: ' + req.params.id);
});
module.exports = router;
Como verás, he incluído dos URL, cada una con su función de middleware oportuna que escribe por la salida directamente (como un servicio REST) sin redirigir a ninguna vista:
- La mapeada en “/carreras” escribe un mensaje directamente.
- La mapeada en “/:id” tiene más complejidad: espera un parámetro en la URL que está identifiado por “:id”. Este valor lo lee con req.params.id, y lo incluye en la salida. Ya puedes imaginar lo fácil que es hacer un servicio REST con Express :).
Enganchamos este nuevo router que está en el fichero coches.js
Fácilmente (que diría el amigo de Matías). Nos vamos a app.js y conectamos el router nuevo con la aplicación.
...
var coches = require('./routes/coches');
...
app.use('/coches', coches);
...
Pero hay una cosa particular ahora: el router está asignado a “/coches” y dentro del router están sus respectivos mapeos a los middleware. La consecuencia es que las URL se sumarán:
- http://localhost:3000/coches/carreras devolverá “Response con un coche de carreras”.
- http://localhost:3000/coches/renault devolverá “Response con un coche renault”.
Si quieres descargar el repositorio en este punto lo he tageado como https://github.com/4lberto/expressAdictos/releases/tag/WithCoches.
Quizá la forma más adecuada de organizar ciertas funciones de middleWare y routers, sea empleando ficheros con módulos de NodeJS para facilitar la mantenibilidad. Si no sabes cómo funciona el sistema de módulos de NodeJS, te lo explico en este apartado de otro tutorial. En este otro apartado te explico cómo usar TDD con Mocha y Chai para módulos de NodeJS, que también te valdrá para Express.
4.4. Modelo
Del modelo no voy a decir mucho: se trata de los datos que se pasan a la vista desde el controlador, y se hace en formato de objectos de Javascript: pares key-value anidables, osea JSON.
El modelo se puede obtener desde cualquier fuente que pueda emplearse en otro lenguaje:
- El request de entrada.
- Una base de datos.
- Ficheros locales.
- Otros servicios publicados en la nube.
El modelo, una vez construído, irá indefectiblemente en la llamada a la vista desde la función de middleware o controlador.
4.5. Vista
Es lo que ve el consumidor del servicio web que creamos o de la página Web. Por principio del MVC es la parte “menos inteligente”, ya que no tiene que realizar ningún procesamiento, simplemente pintar de forma adecuada la información que le pasa el modelo cuando le redirige la salida.
En el generador de Express que estamos utilizando en este tutorial, las vistas están ubicadas en el directorio “views”. Por defecto vienen dos ficheros: index.jade y error.jad.
¿Cómo indica el controlador que tiene que redirigir a una vista? En el código del controlador, concretamente en el que enlaza la URL del servidor con una función de middleware, se indica el nombre al que redirige:
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
Como puedes ver, con res.render, se indican dos elementos:
- La página: index (correspondiente a index.jade)
- El modelo que se pasa en formato de objeto Javascript: title:’Express’.
Una cosa que seguro que te llama la atención es que las vistas no están en HTML puro sino en un lenguaje de marcado llamado “JADE”. En realidad es un motor de plantillas para faciliar la escritura de las vistas.
El uso de este motor de plantillas queda indicado en el código de app.js:
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'jade');
Vamos a ver el contenido de la plantilla principal: index.jade
extends layout
block content
h1= title
p Welcome to #{title}
Que de cara al usuario se transforma en:
<!DOCTYPE html>
<html>
<head>
<title>Express</title>
<link rel="stylesheet" href="/stylesheets/style.css">
</head>
<body>
<h1>Express</h1>
<p>Welcome to Express</p>
</body>
</html>
Como puedes ver, sí que es una forma más sencilla de escribir HTML, aunque me pregunto cómo de flexible será si se quieren utilizar plantillas más ricas… Por ejemplo se podría usar esta adaptacion de Bootstrap 3 de Twitter para Jade: https://github.com/ALT-F1/bootstrap3-jade-node-express-grunt, pero esto daría para otros tutoriales.
Lo que nos debe interesar es la forma de integrar el modelo que nos han pasado (title:’Express’) en la plantilla. La susititución de la variable es muy sencilla:
p Welcome to #{title}
Efectivamente, se cambiar #{title} por el valor title del modelo, que es ‘Express’. Jade permite hacer cosas más complejas, como iterar sobre un array del modelo, incluir código de procesamiento básico, condicionales… Si quieres más información de Jade, puedes consultarla en su página propia: http://jade-lang.com/.
4.6. Elementos Públicos
En una aplicación Web no todos son recursos dinámicos que necesitan de un middleware para procesar. También tenemos recursos estáticos: imágenes, hojas de estilo, scripts…
Como podrás suponer, dentro de la estructura creada por el generador de express, tenemos la carperta “public”, donde podremos ubicar todos esos ficheros.
Esta carpeta está configurada en el fichero app.js, como no podría ser de otro modo:
app.use(express.static(path.join(__dirname, 'public')));
Importante: la carpeta public se mapea en el directorio “/”. Es decir, el directorio public/images de nuestro disco será http://localhost:3000/images directamente.
Por cierto, el resultado final lo puedes descargar aquí: https://github.com/4lberto/expressAdictos
5. Conclusiones
El mundo de Javascript en la parte servidora avanza imparable, y uno de los principales causantes es su capacidad para servir contenidos en el mundo del HTTP, bien como páginas Web o bien como sericios REST, tan de moda últimamente.
El principal exponente de los frameworks para servir contenidos dinámicos en NodeJS es Express. Se trata de un framework MVC que hace la competencia al siempre presente PHP, Spring MVC o los disponibles de ASP .NET
En este tutorial hemos visto los primeros pasos que tenemos que dar para desrrollar en este entorno, viendo desde la instalacion de un generador que nos facilita la creación de una plantilla de base, hasta los archivos y directorios más importantes donde debemos intervenir para crear una aplicación a nuestro gusto.